WordStat 5.0 New Features
DICTIONARIES PAGE
- New pre-processing option allows one to create his own text pre-processing EXE or DLL (sample English porter stemmer and n-grams transformation are include).
- A new lemmatization monitoring dialog allows reviewing substitutions, overriding existing ones by creating custom substitutions.
- Disambiguation rules with Boolean (AND, OR, NOT) and proximity operators (NEAR, AFTER, BEFORE) may now be added to categorization dictionaries (click on thumbnail to see a screen shot).
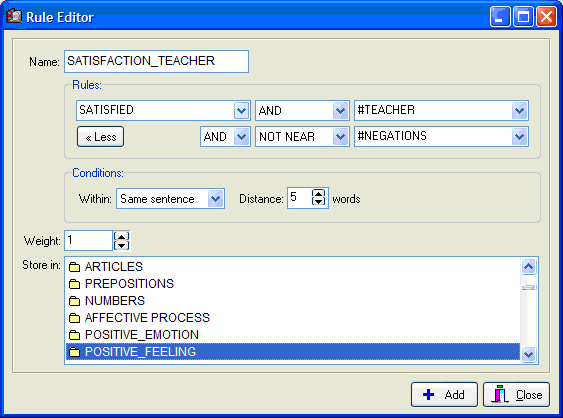
- "As shown" level setting allows setting the categorization level to the way the dictionary tree is displayed.
- Ability to create unbreakable categories (overriding the level setting).
- Categorization dictionaries may now be printed or exported to XML.
- Ability to merge existing dictionaries.
- Improved contextual menus for faster dictionary editing.
OPTIONS PAGE
- A new option allows one to include cases with missing values on independent variables (override existing listwise exclusion).
- Feature to select a variable to weight cases.
- New threshold to remove items occurring in more than a specified % of cases.
FREQUENCIES PAGE
-
 Ability to create
files of keyword frequency norms and compare existing frequencies
to previously saved norm files.
Ability to create
files of keyword frequency norms and compare existing frequencies
to previously saved norm files.  An entirely
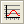
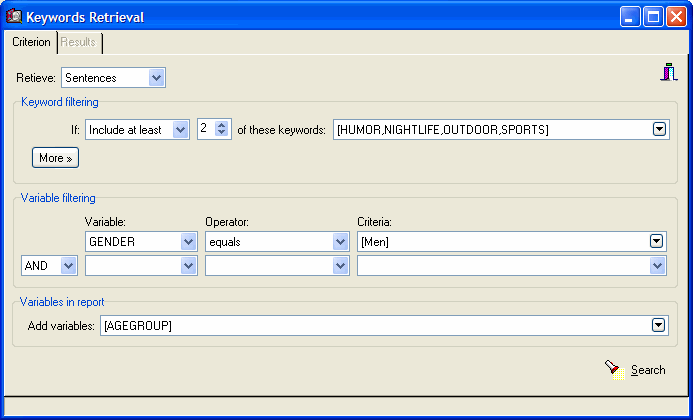
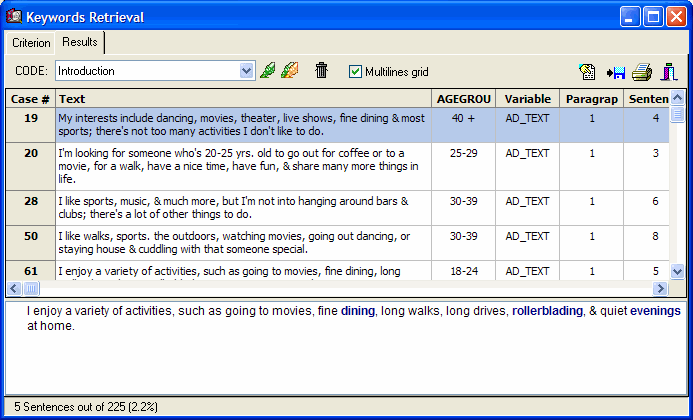
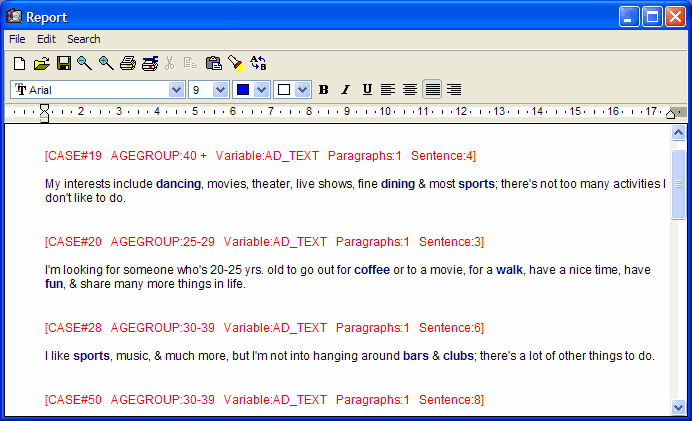
new keyword retrieval dialog allows one to extract documents,
paragraphs or sentences with user defined combination of keywords.
Retrieved text segments may optionally be tagged using QDA Miner
codes (click on the thumbnails below to see screen shots).
An entirely
new keyword retrieval dialog allows one to extract documents,
paragraphs or sentences with user defined combination of keywords.
Retrieved text segments may optionally be tagged using QDA Miner
codes (click on the thumbnails below to see screen shots).
-
 The full categorization
process may now be stored on disk and applied to documents using
a standalone utility program (WS Document Classifier) or an optional
DLL and command line program.
The full categorization
process may now be stored on disk and applied to documents using
a standalone utility program (WS Document Classifier) or an optional
DLL and command line program.  Optional colored
grid lines.
Optional colored
grid lines. - Included items may be removed temporarily from further analysis.
- Added TF*IDF column (term frequency x inverse document frequency).
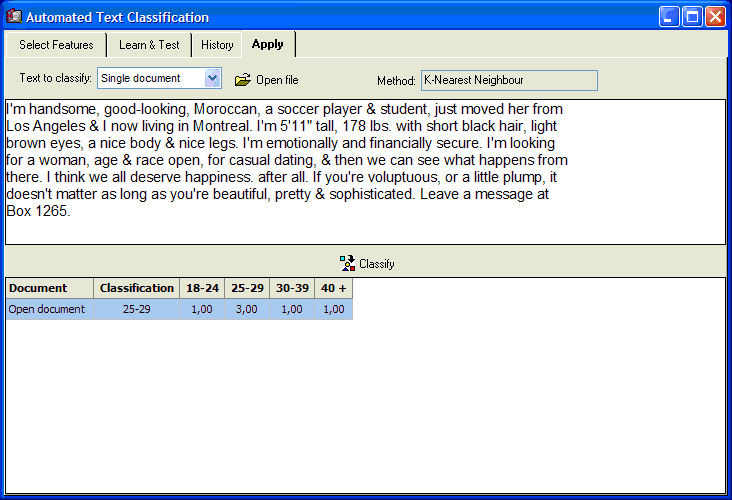
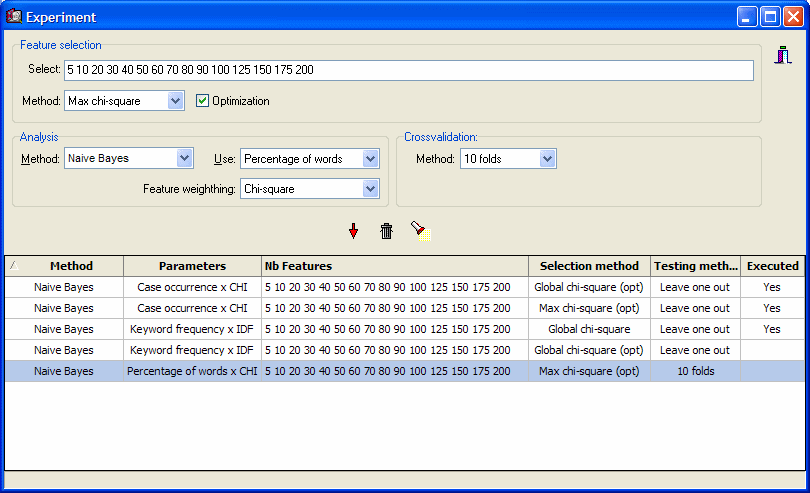
AUTOMATIC DOCUMENT CATEGORIZATION
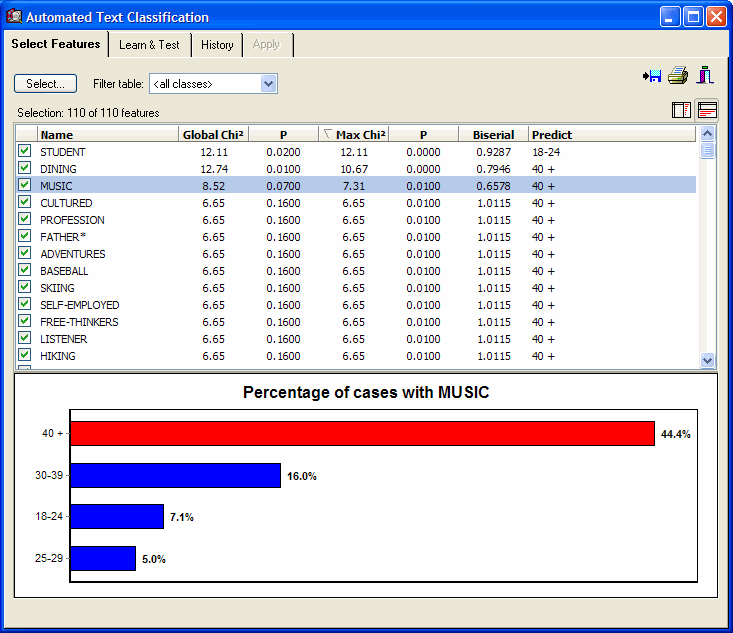
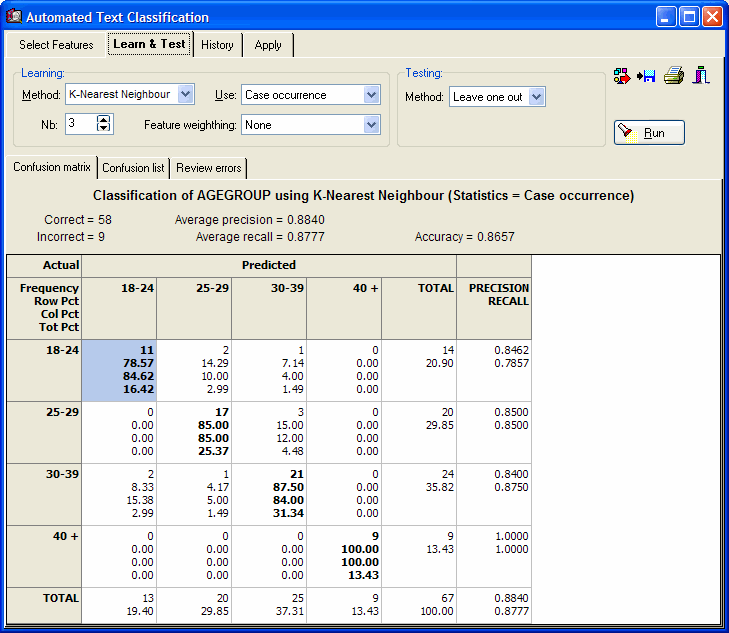
- Naive Bayes and k-nearest neighbors classification methods applied on occurrences, frequencies, percentage of words, etc.
- Feature selection and feature weighting.
- Crossvalidation methods (leave one out, n-folds, split sample).
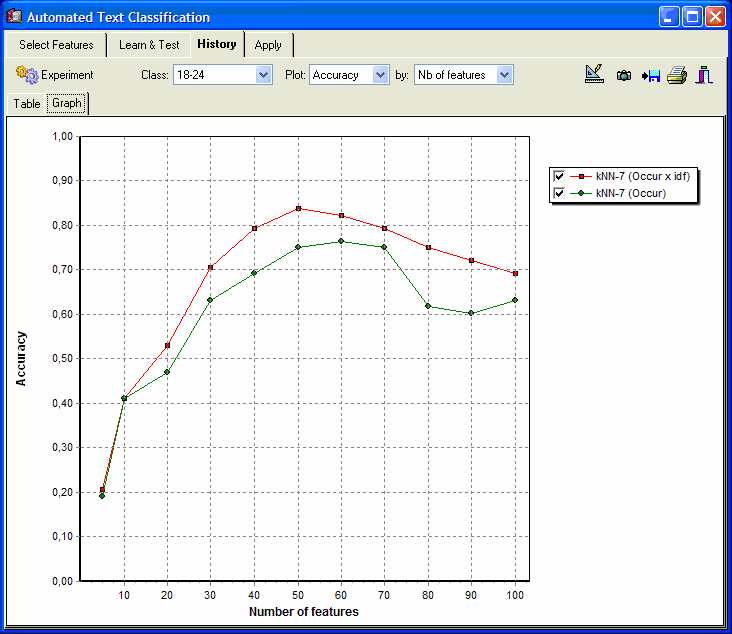
- Batch experiment module and history charts for model optimization.
- Document classification on single texts, list of documents or database.
- The classification model may be stored on disk and applied to external documents using a standalone utility program (WS Document Classifier) or an optional DLL and command line program,
- Optional
colored grid lines.
- Included items may be removed temporarily from further analysis.
KEYWORD-IN-CONTEXT PAGE
- The KWIC page may now be detached and displayed as a stay-on-top dialog.
FEATURE EXTRACTION PAGE
- Phrase finder page has been moved to the feature extraction page.
- A new Unknown Words finder allows one to quickly identify misspelled words, acronyms, technical words, proper nouns and either replace, ignore or assign them to the categorization dictionary.
CLUSTER ANALYSIS
- Added probabilistic versions of Jaccard and Sorensen (or Dice) coefficients.
- Added second order clustering of keywords (based on the similarity of co-occurrence patterns rather than mere co-occurrences).
- Ability to select a single cluster and retrieve associated documents.
- New option to hide single item clusters in dendrograms and multidimensional scaling plots.
PROXIMITY PLOT
- New option to retrieve documents or text segments containing two specific keywords.
OTHERS
- The document conversion wizard can now extract text from PDF files.
- Categorization models and classification rules may be saved on disk.
- "Anchor to floor" lines on 3D charts (MDS and correspondence plot).
- WS Document Classifier, a small standalone application to apply previously saved categorization and classification models to external documents.
- Separately sold DLL and command line versions of WordStat for standalone content analysis and automatic classification of documents (not available yet).
- Major speed improvements. The table below provides some speed comparisons between v4 and v5. This test was performed on a 1.2Ghz Pentium 3 computer.
|
TASK
|
VERSION
4.0 |
VERSION
5.0* |
SPEED
IMPROVEMENT |
| Word frequency of 11,314 newsgroup messages (3,249,029 words) | 5m 52s | 2m 59s | x2.0 |
| - with lemmatization & stop list | 6m 45s | 3m 11s | x2.1 |
| - categorized using Regressive Imagery Dictionary (RID) | 10m 4s | 2m 24s | x4.2 |
| - categorized using Linguistic Inquiry and Word Count (LIWC) | 10m 52s | 2m 52s | x3.8 |
* Speed improvements may differ on other computers and in the final v5.0 release.
New features in version 4 can be viewed here.
