WordStat 6.1 New Features
- A new multilingual user interface (English, French and Spanish)
- Improved linguistic support with integrated dictionaries and thesauruses for five languages (English, French, Spanish, German and Portuguese) to assist the development of taxonomies and content analysis dictionaries
- A 50% improvement over its predecessor in processing speed, allowing one to analyze up to 30 million words per minute
WordStat 6 New Features
1. NEW AUTOMATIC SUGGESTION FEATURE 
On the frequency page, an optional panel (right) automatically shows for the selected items (words or content categories) all related leftover words (synonyms, antonyms, hyponyms, hypernyms, words with same stem, etc.), allowing one to select relevant ones and assign them to a category. Please note that this feature is fully functional only when analyzing English document. When analyzing documents in other languages, the panel will show words with a similar root form.
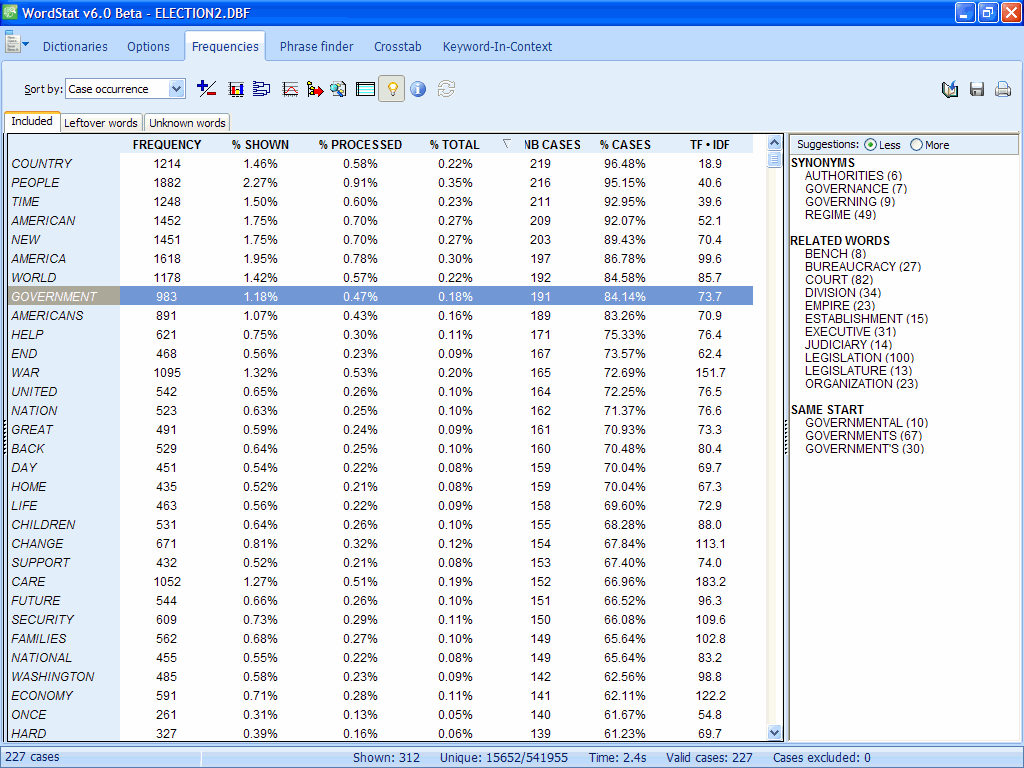
2. INTEGRATED DRAG & DROP TO DICTIONARY
The drag and drop dictionary editor has been replaced with a new drag and drop panel available on the left side of the Frequencies, Crosstab and Phrase Finder pages, allowing easier assignments to the categorization dictionary, the exclusion list and to the new substitution list. Assignments to a new category can be achieved by dropping one or several items on the NEW CATEGORY tree icon.
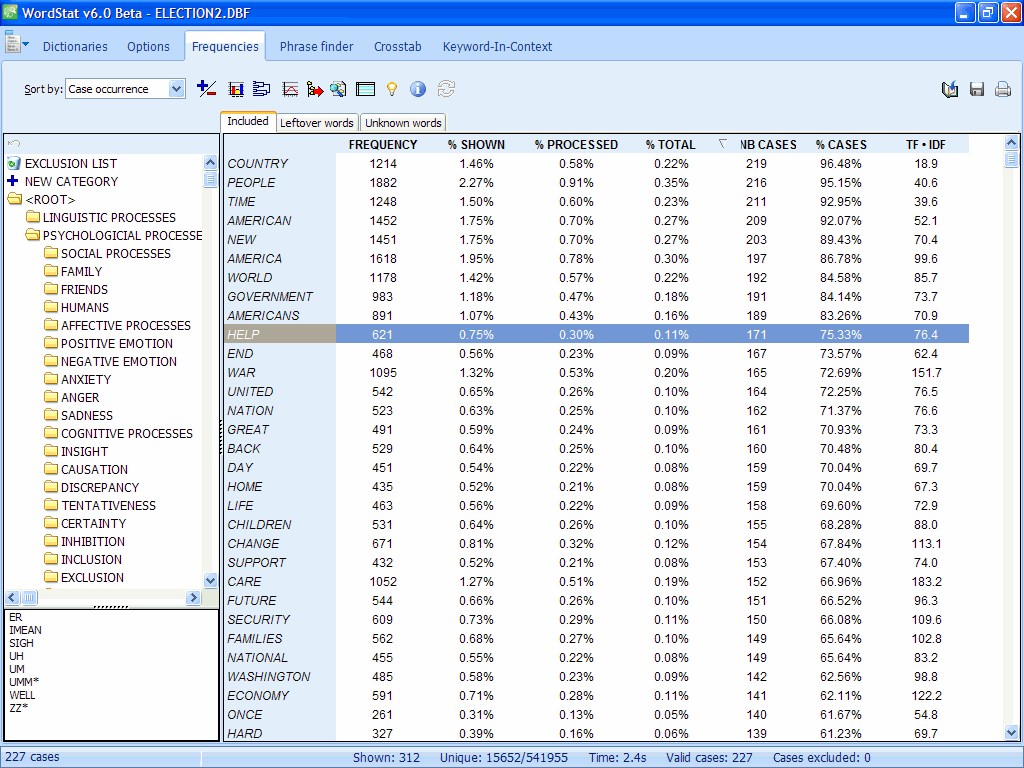
3. CLUSTERING AND CORRESPONDENCE ANALYSIS OF PHRASES
One can now perform cluster and correspondence analysis of phrases, without the need to save them into a categorization dictionary. A dialog also allows one to add to this list, frequent words and save extracted phrases into a new dictionary.
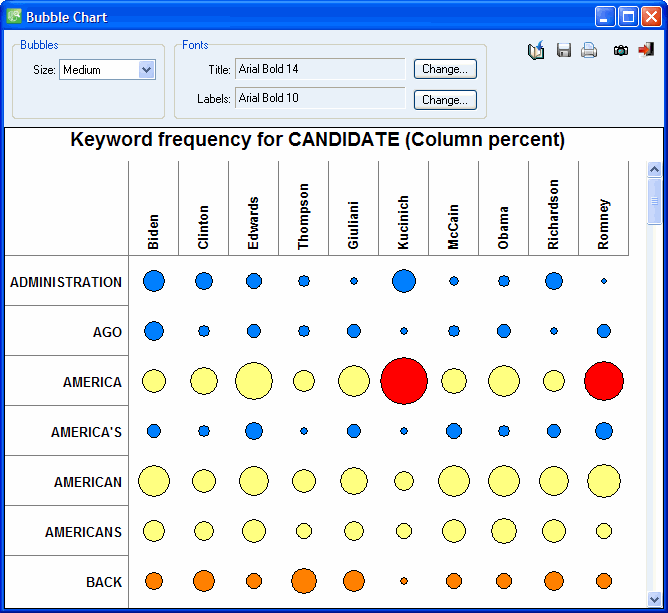
4. STACKED BAR CHART AND BUBBLE CHART
Two new charts have been added to display the relationship between codings and variables: The stacked bar chart allows one to display relative or absolute frequency of codings by stacking them for each class of the categorical or numerical variable. It allows one to quickly show the relationship of parts to the whole or to emphasize the sum of several codes.
The bubble chart is a graphic representation of crosstab tables where relative frequencies are represented by circles of different diameters. This type of chart allows one to quickly identify high and low frequency cells and is thus especially useful for presentation purposes. Many features of the chart can be customized to highlight specific findings. Rows and columns can be moved freely or deleted, and one can adjust the color of each cell as well as the fonts used.
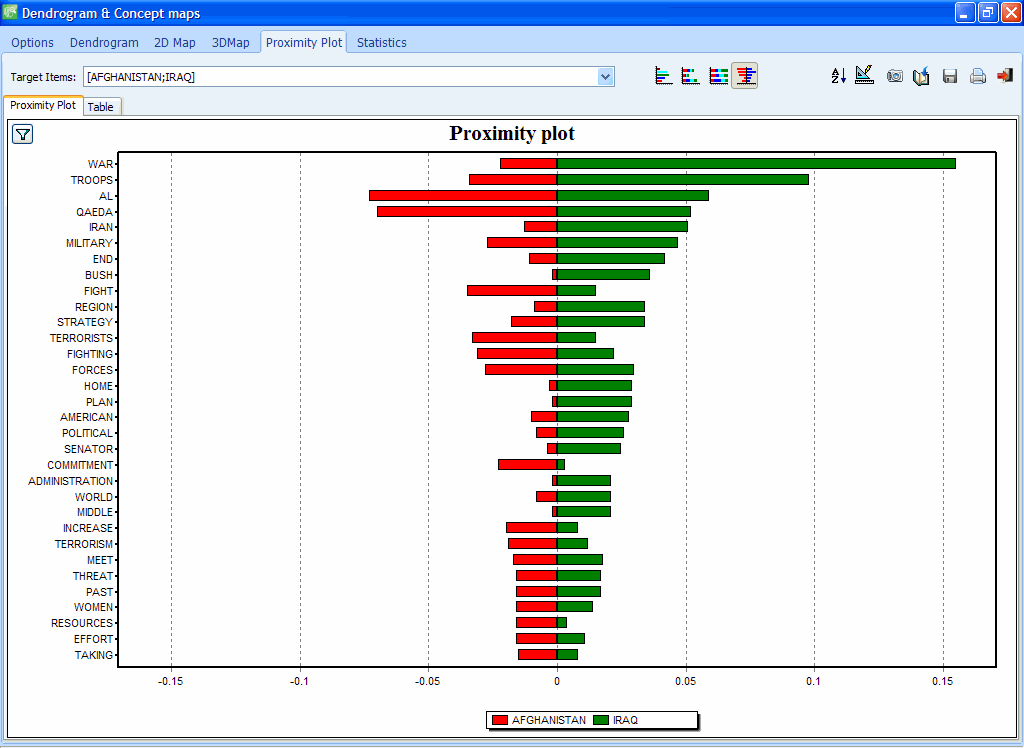
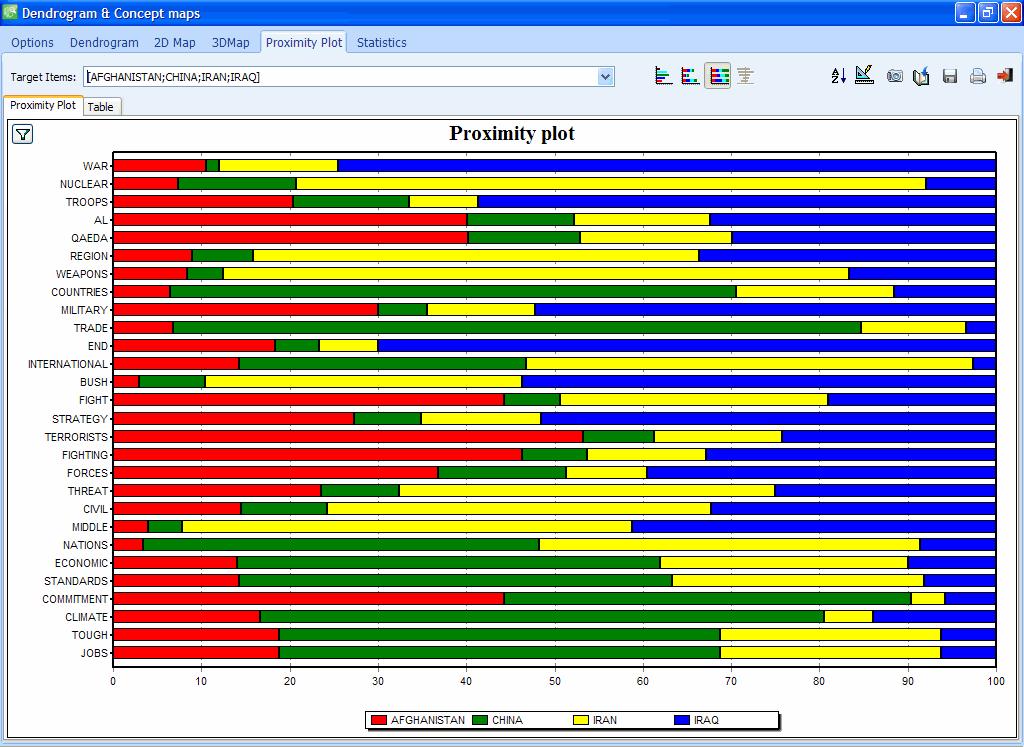
5. REDESIGNED PROXIMITY PLOT
Proximity plot now produces high definition graphics and can now be used to display the proximity from more than one keyword using dual and stacked bar charts.
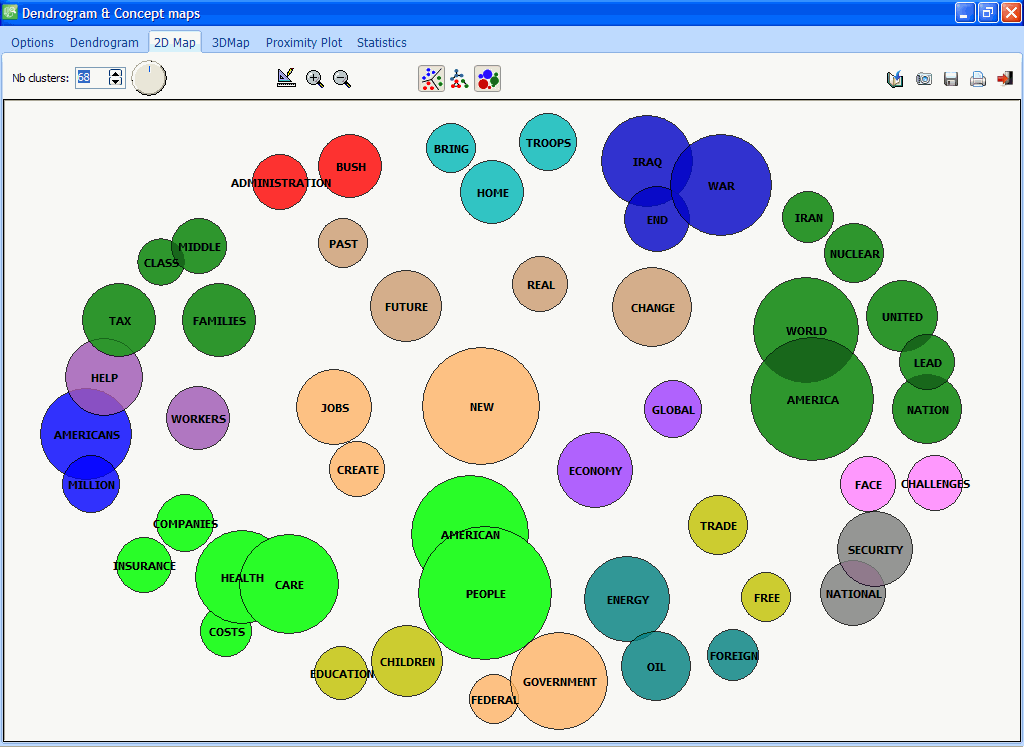
6. IMPROVED MULTIDIMENSIONAL SCALING PLOTS
One can now display the frequency of terms in MDS 2D and 3D plots using bubble plots. Also a new constrained clustering algorithm now allows one to preserve the clustering structure in multidimensional scaling plots, making the interpretation of 2D and 3D MDS maps a lot easier and more consistent with the clustering solutions.
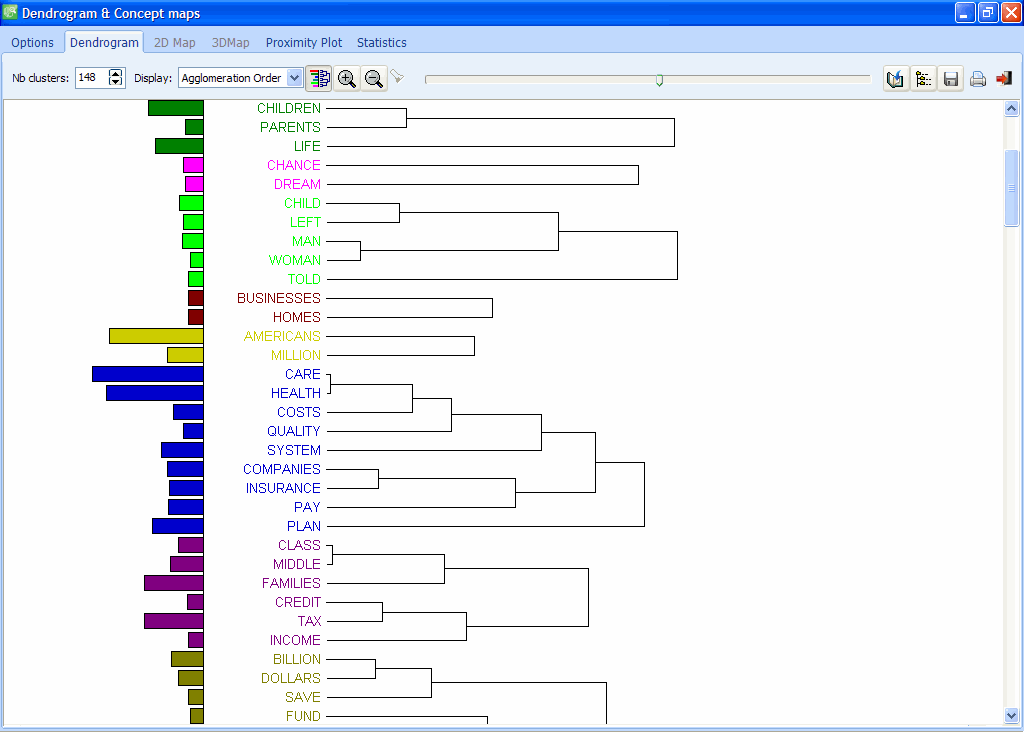
7. IMPROVED DENDROGRAMS
One can now display the term frequencies along with dendrograms using a bar chart.
8. CROSSTAB BY TWO VARIABLES
The CROSSTAB page now allows one to examine the relationship between words or content categories and the combined values of two variables (for example: Gender x Age).
9. AUTOMATIC RETRIEVAL AND CODING OF CONTENT CATEGORIES
A new button on the FREQUENCIES page allows one to retreive all paragraphs or sentences matching any one of the content categories and attach a corresponding QDA Miner code to it. If a specific content category has no corresponding codes in the project codebook, a new one will me automatically created.
10. NEW SUBSTITUTION FEATURE
The Lemmatization pre-processing feature has been replaced with a more flexible substitution process. This new process not only supports existing lemmatization routines but allow users to create their own substitution process for lemmatizing text in a language not currently supported by WordStat or to automatically correct spelling mistakes without altering the original documents. The substitution process may also be used for pre-categorization and used in combination with a categorization dictionary.
11. UNDO FEATURE FOR DICTIONARY EDITING
All modifications made to the exclusion list, the categorization dictionary and to the new substitution process are now monitored and may be undone.
12. IMPROVED LINGUISTIC RESOURCES
The internal linguistic resources for the English language have been greatly improved, with the upgrade to WordNet 3 and the addition of a third thesaurus.
13. SUPPORT OF THE REPORT MANAGER
WordStat now integrates the Report Manager features introduced in QDA Miner 3.0, allowing one to store in a single location, documents, tables, graphics, and text outputs produced by QDA Miner and WordStat. The Report Manager is structured like an outliner (similar to the SPSS Output Viewer), allowing one to easily view items, edit them, reorganize them and write draft versions of reports.
Buttons like thishave been added to many dialog boxes to automatically store tables, charts and text into the Report Manager. Holding the Shift key while clicking this button will a display dialog box that allows you to customize the title and enter a description of the item saved.
14. IMPROVED PHRASE EXTRACTION
A new algorithm has been implemented to remove redundant or superfluous word sequences.
15. IMPROVED PHRASE OVERLAPS PANEL
One can now perform operations on phrases listed in the overlap panel (drag & drop to a dictionary, get a KWIC list or remove them)
16. IMPROVED EXPORTATION OF DATA STATISTICS
The dialog for exporting data statistics to disk has been improved with new options to select variables to be added to the report and the ability to export occurrence of content categories into multinomial variables. An option panel also allows one to preview the data to be exported.
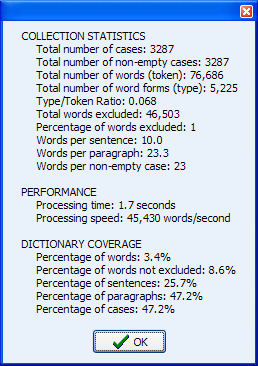
17. DOCUMENT AND DICTIONARY COVERAGE STATISTICS
On the FREQUENCIES page, a new button allows one to get various document statistics (number of words, sentences, paragraphs, words per sentence, etc.) and assess the coverage of the content analysis dictionary (percentage of words, sentences, paragraphs, documents and cases containing categorized items).
18. EXPORTATION OF CO-OCCURRENCE DATA TO SOCIAL NETWORK ANALYSIS SOFTWARE
Co-occurrence data may now be exported to popular social network analysis software such as UCINET, Pajek, NetDraw and NetMiner.
19. EXPORTATION TO SPSS FILES
All tables and data matrix may now be exported directly to SPSS .SAV data files.
20. VERTICAL LABELS ON TABLES AND GRAPHICS
A new button has been added to various charts and tables to display labels of columns or on the bottom axis vertically rather than horizontally.
21. CREATION OF QDA MINER CODEBOOK CATEGORIES
In the keyword retrieval dialog, it was possible with WordStat 5.1 to assign an existing QDA Miner code to retrieved text segments. It was also possible to add new codes, but it was not possible to create new categories in the codebook. WordStat 6 now allows one to add categories to an existing QDA Miner codebook or create a new codebook.
22. KWIC LIST ON MULTIPLE ENTRIES
The user defined edit box in the Keyword in Context dialog now supports the specification of several entries (separated by semicolons). Selecting several rows of a table and calling the KWIC list will also produce a KWIC list on all selected items.
23. SUPPORT OF QDA MINER'S CASE DESCRIPTORS
Support QDA Miner case descriptors allow one to define more detailed case labels based on several variables.
24. SELECTION OF INDEPENDENT VARIABLES
A new option now allows one to select new independent variables without the need to go back to QDA Miner or Simstat.
25. SELECTION BY NUMBER OF ITEMS
A new option allows one to limit the number of items retrieved to a specific number (for example, select the 100 most frequent words, or 200 items with the highest TFxIDF value.
26. ABILITY TO SPECIFY SPECIAL EMBEDDED CHARACTERS
A new option allows one to identify special characters that will be recognized as integral parts of a word (or token) to the condition that they are immediately surrounded on both sides by other valid characters. For example, entering the period and the @ sign in this list will keep email addressed intact and retrieved those. Entering the period and comma signs in this list and the $ sign in the other list of valid characters will retrieve items like $1,000 or 3.1415. Words at the end of sentences will still be retrieved without the period sign since this period is likely to be followed by a space or a carriage return (thus not surrounded by alphanumeric characters).
27. ABILITY TO REAPPLY PRIOR SPELLING CORRECTIONS
All replacements of misspelling performed in text using the "unknown words" feature are automatically saved. When using this same feature on a new text collection, the program will automatically suggest reapplying corrections made previously.
28. NEW ALGORITHM FOR FASTER CORRESPONDENCE ANALYSIS
We implemented a much faster correspondence analysis algorithm. See timing results below.
WORDSTAT 5.1
WORDSTAT 6.0
29. IMPROVED DICTIONARY BUILDER
The dictionary builder has been improved in several ways. It now relies on the latest version of WordNet 3.0 (the prior version was using WordNet 1.7). A new option has been added to display only words present in your text collection (leftover words). It is also about twice as fast as prior versions.
30. IMPROVED BASIC SUGGEST DIALOG BOX
The Basic Suggest feature has been redesigned. It now provides more suggestions and allows one to filter suggestions to display only words currently in the current document collection. The speed of this feature has also greatly improved.
31. INTERACTIVE 2D CORRESPONDENCE PLOT
One can now right-click a keyword in a correspondence and produce Keyword-in-context or a keyword retrieval listing. One may also use the right click to remove either a keyword or a class of the categorical variable and recalculate the correspondence analysis, allowing one to easily remove outliers and display relationship among remaining items.
32. IMPROVED PROCESSING OF DATES
When a date variable is selected, in the Crosstab page, a dialog box appears allowing one to group all dates by decades, years, months, quarters or days of the week.
33. IMPROVED "ADD TO CATEGORIZATION" COMMAND
When selecting several words or phrases in a table and then selecting the ADD TO CATEGORIZATION DICTIONARY command now offers to add all of them at once to a single category.
34. IMPROVED DIALOG BOX FOR ADDING ITEMS TO A DICTIONARY
The new dialog box allows the assignment of items to a new category in a single step (users no longer need to create the category first and then assign words or phrases to this newly created category).
35. REDESIGNED DICTIONARY PAGE
Easier to learn and use dictionary page.
36. REDESIGNED CASE FILTERING DIALOG
Easier to use case filtering dialog, similar to QDA MIner (with the ability to call the prior filtering dialogs).
37. EASIER CUSTOMIZATION OF CORRESPONDENCE ANALYSIS
The customization of correspondence plots is now easier with a new dialog box for basic editing.
38. ASSIGNMENT TO CATEGORIES FROM THE KWIC DIALOG
One may now assign a word or a phrase to a category from the KWIC page by positioning the editing cursor of the text box below the table on the word to be categorized or by selecting a phrase and then right-clicking it.
39. NEW COMPARISONS WITH TEXT CORPUS
New word frequency data files for comparing any text collection to word frequencies in the British National Corpus and the Open American National Corpus
New features in version 5.1 can be viewed here.
