 |
|
LIST OF FEATURES
Text management features:
- Storing and editing of documents in Rich Text format.
- Project files organized by cases, each case can contain up to 2030 variables including multiple documents, numeric, nominal/ordinal, date or Boolean values.
- Importation from various file format such as Excel, Access, Paradox, dBase, SPSS, NVivo, N6, Atlas.ti, Transana, Transcriber, etc.
- Document conversion wizard allows one to easily import documents from various file format and to automatically extract numeric and alphanumeric values.
- Cases may be grouped by any numeric, nominal or ordinal variable.
- Easy filtering of cases.
Coding features:
- Easy creation and edition of codebooks.
- Fully hierarchical codebook
- Intuitive drag and drop assignment of codes to text segments.
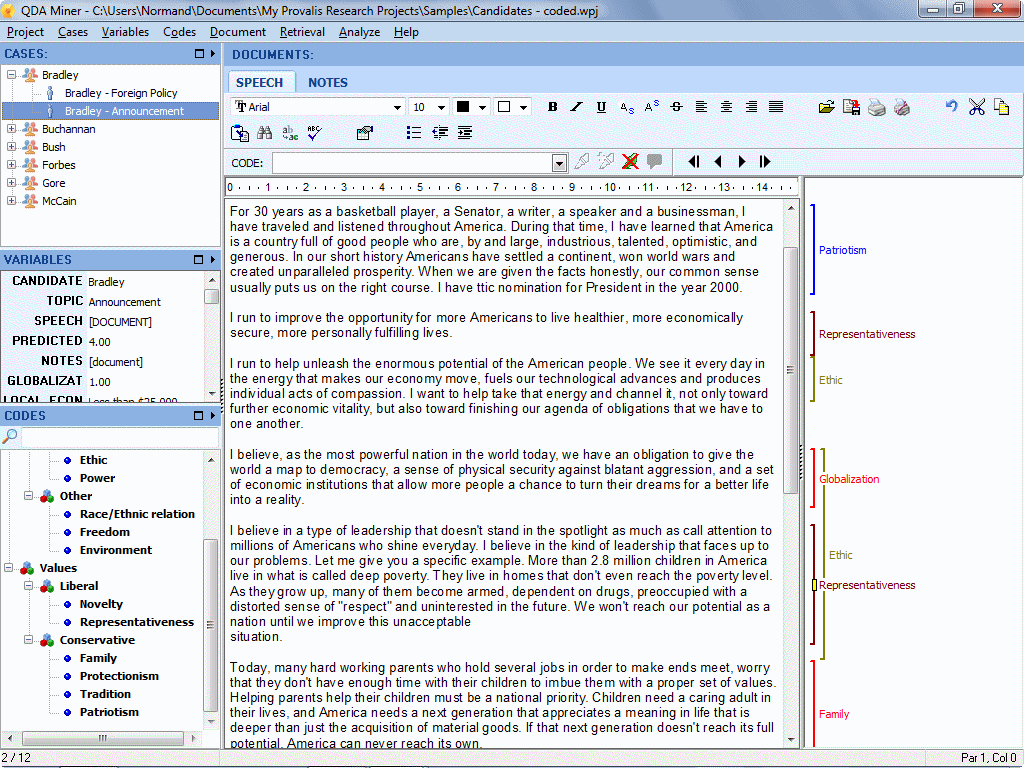
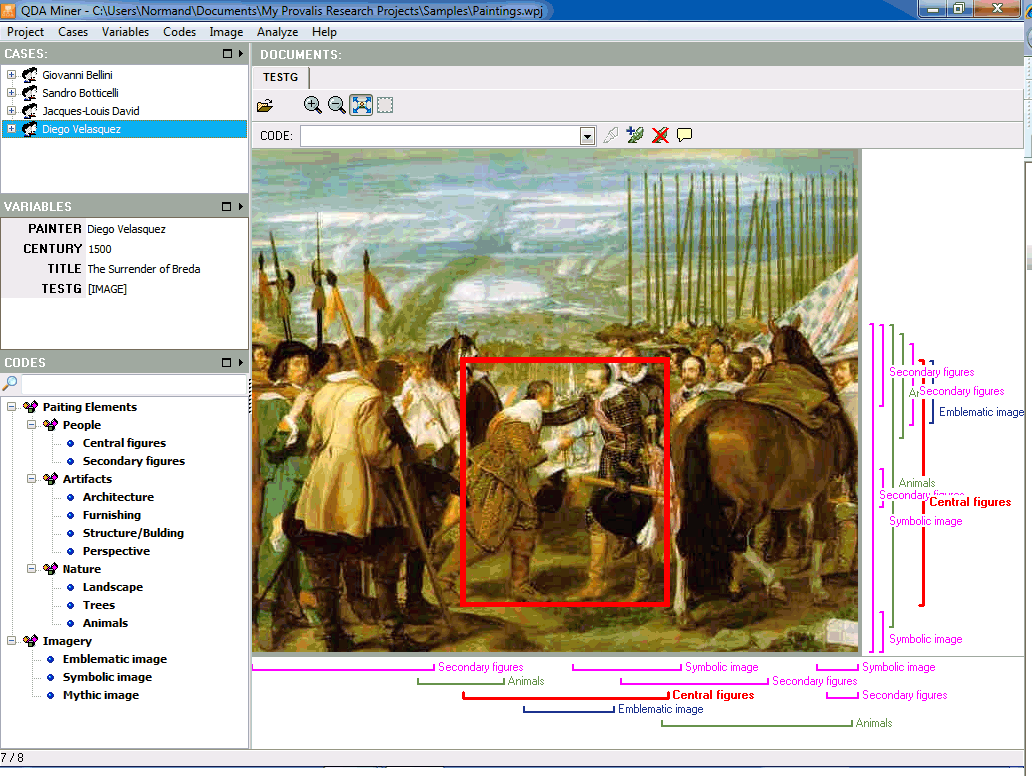
- Notes can be assigned to projects, codes and coded segments.
- Code merging, splitting and search and replace.
- Ability to import codebooks from other projects.
Text Retrieval and Coding analysis features
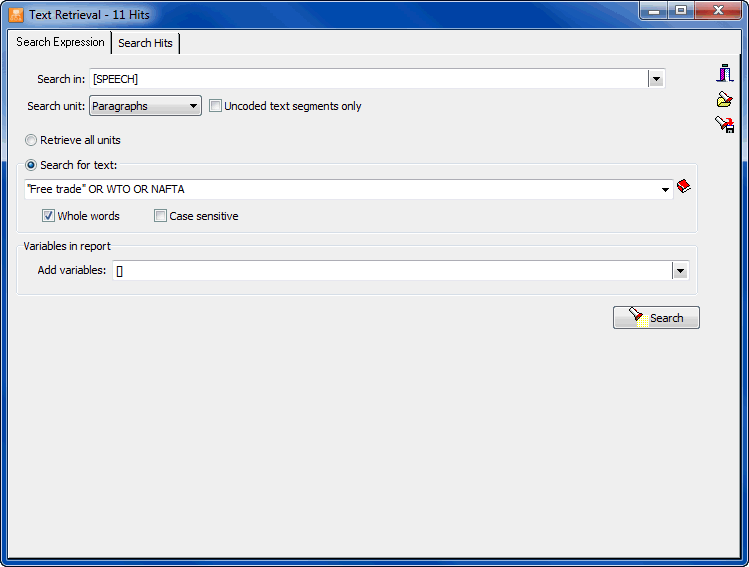
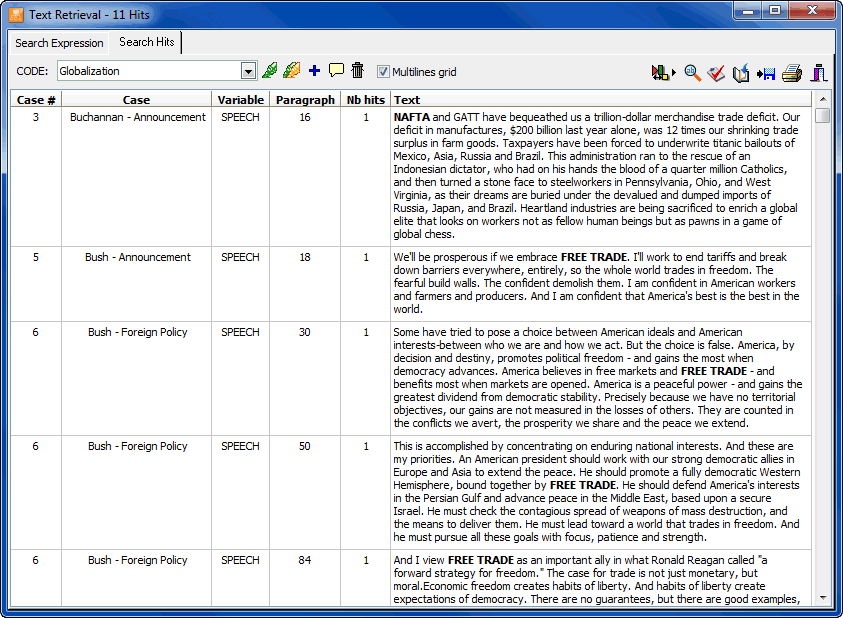
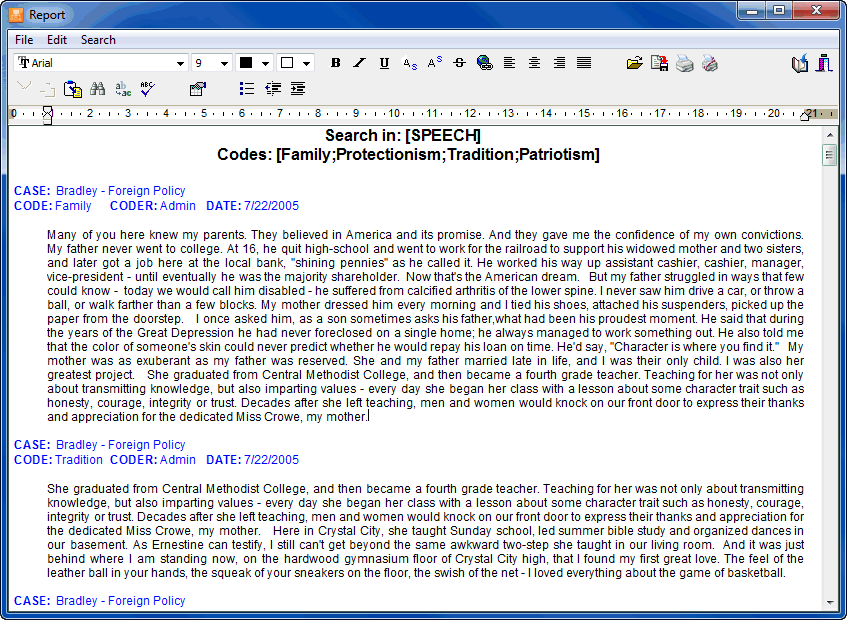
- The Text Retrieval tool searches for specific text patterns in documents. Complex search patterns may be performed using Boolean operators. This search can be performed on all documents in a project or restricted to specific ones or to some coded segments. Retrieved segments may then be coded or saved to disk (as new project, in HTML, Excel, or delimited text files.
- The Section Retrieval tool searches structured documents for sections bounded by fixed delimiters. This feature is useful to automatically assign codes to recurring sections within a document or in multiple documents.
- The Keyword Retrieval feature can retrieve any document, paragraph, sentence, or coded segment containing a specific WordStat keyword or a combination of keywords.
- The Coding Frequencies tool allows one to obtain a list of all codes in the current codebook along with their description and various statistics such as their frequency, the number of cases in which they are found, and the total number of words in the associated text segments. This dialog box also allows one to produce bar charts and pie charts from those statistics.
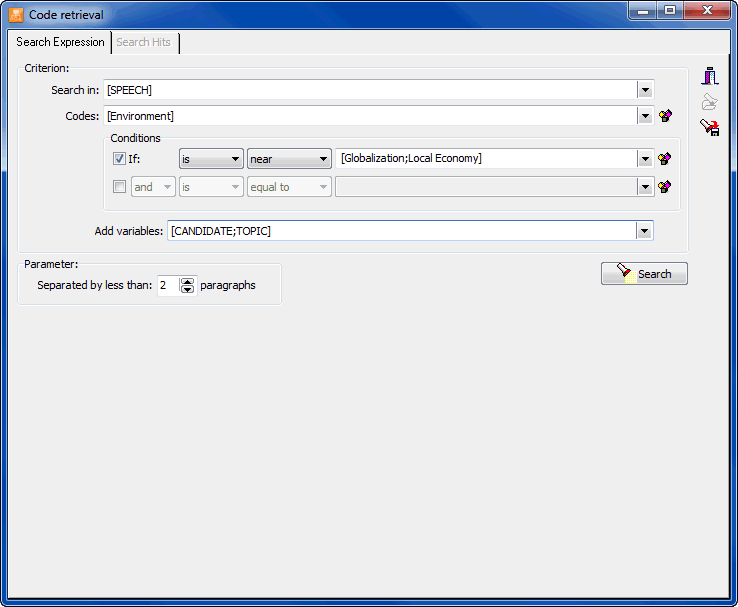
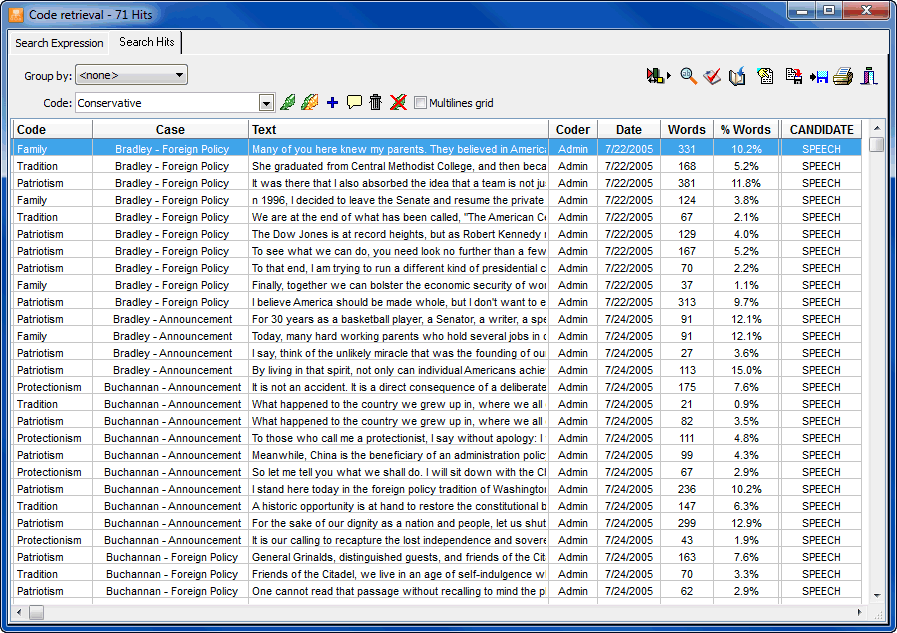
- The Coding Retrieval tool lists all text segments associated with some codes or with specific patterns of codes. Complex search patterns may include criteria such as equality, proximity, overlapping, inclusion, sequential relationships, as well as Boolean operators (AND, OR, NOT).
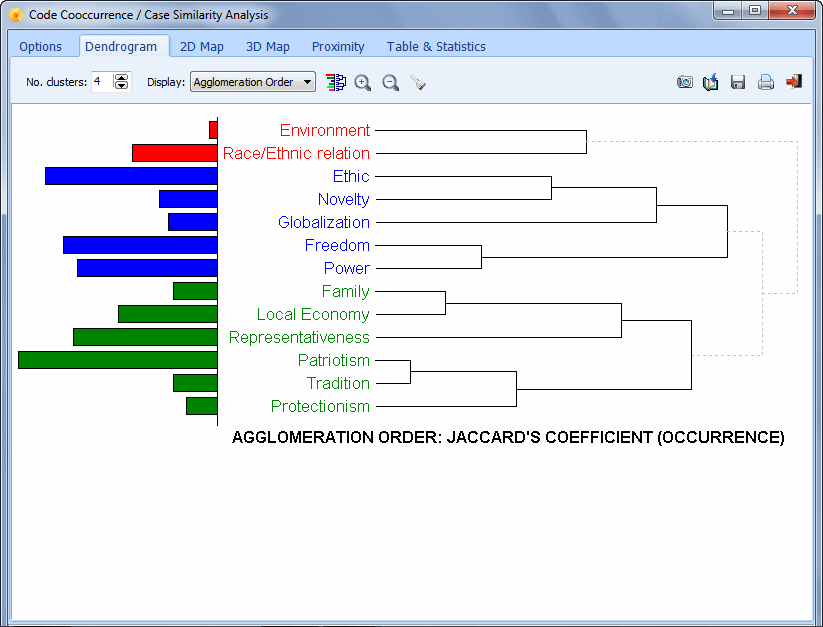
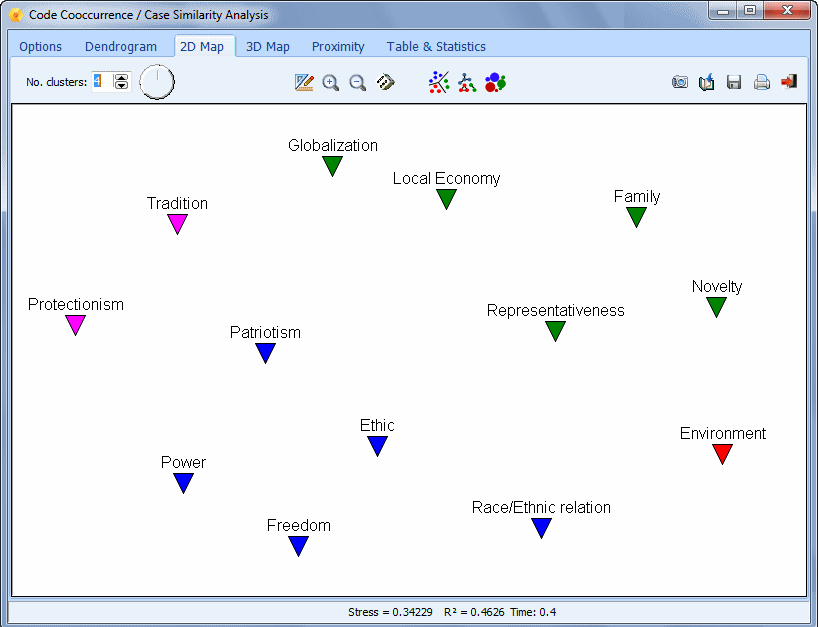
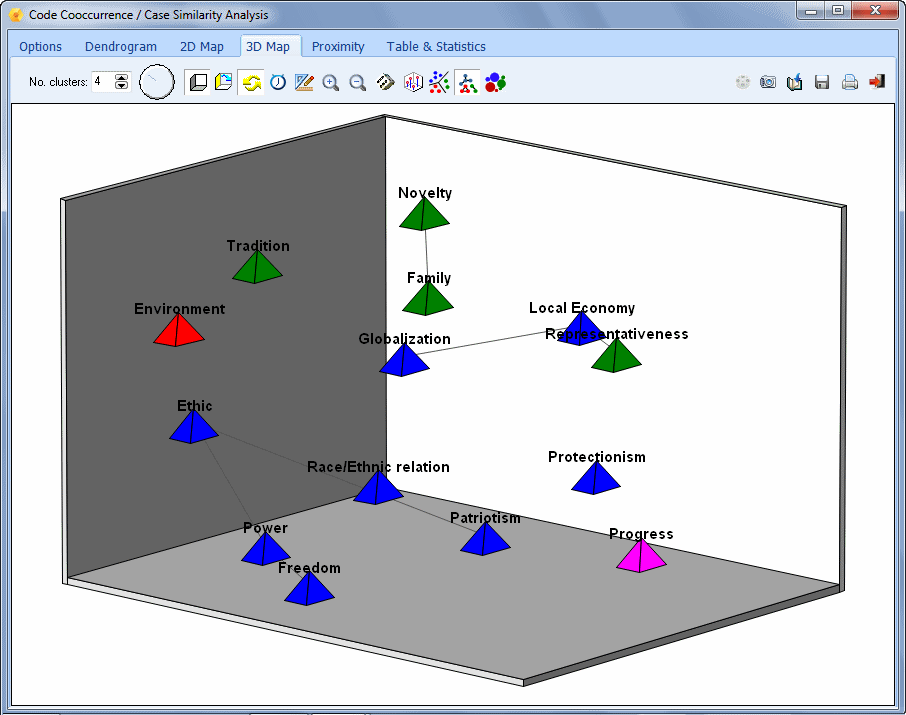
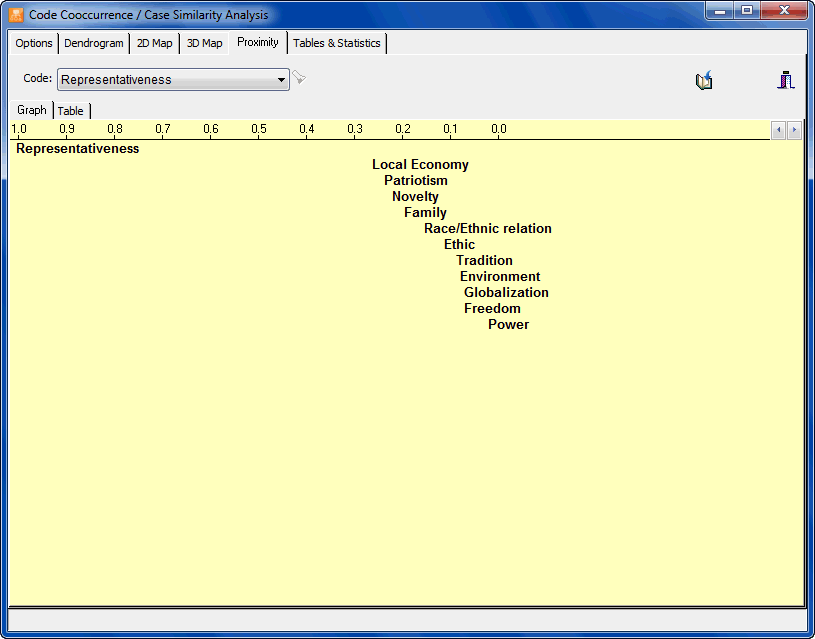
- The Codes Co-occurrences tool uses information about the proximity or the co-occurrence of codes within documents to explore potential relationships among them as well as similarities among cases. This feature gives access to various statistical and graphic tools such as cluster analysis, multidimensional scaling, and proximity plots.
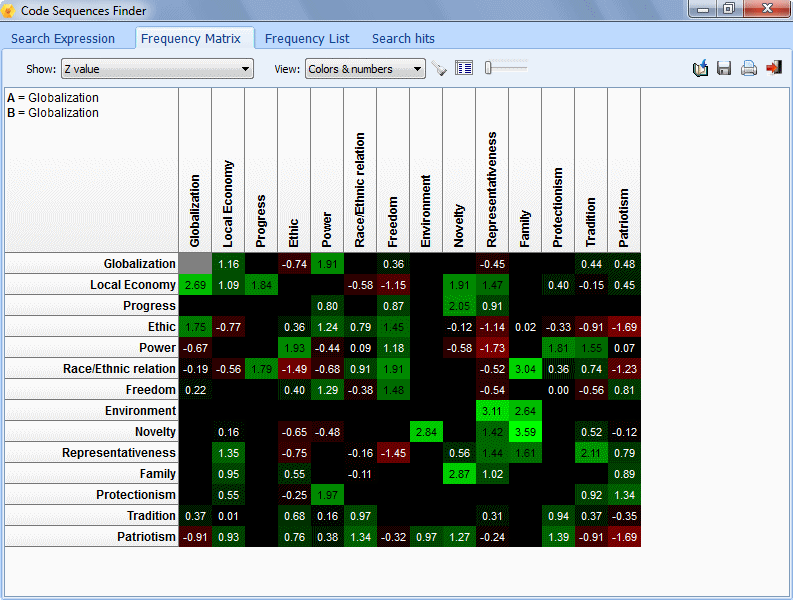
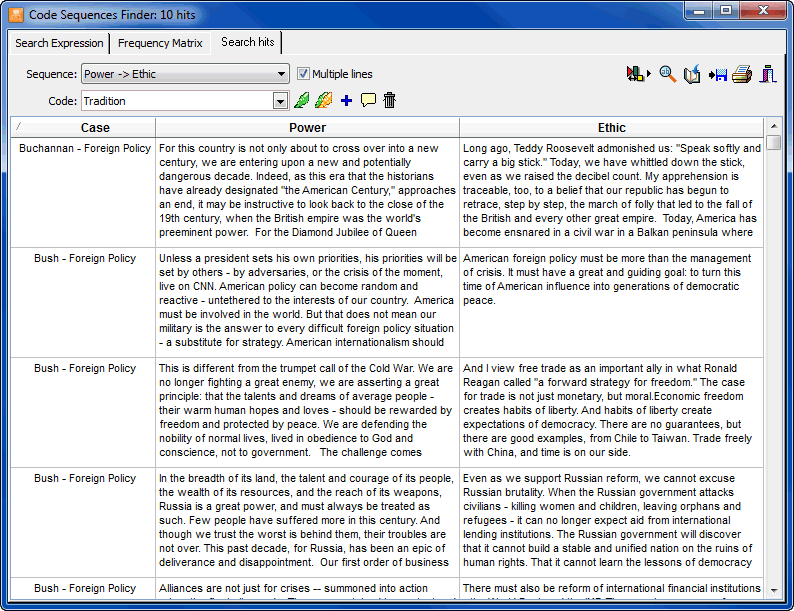
- The Coding Sequences tool can be used to identify recurring sequences of codes. This feature can produce frequency lists of all sequences involving two selected sets of codes as well as the percentage of time one code follows or is followed by another one.
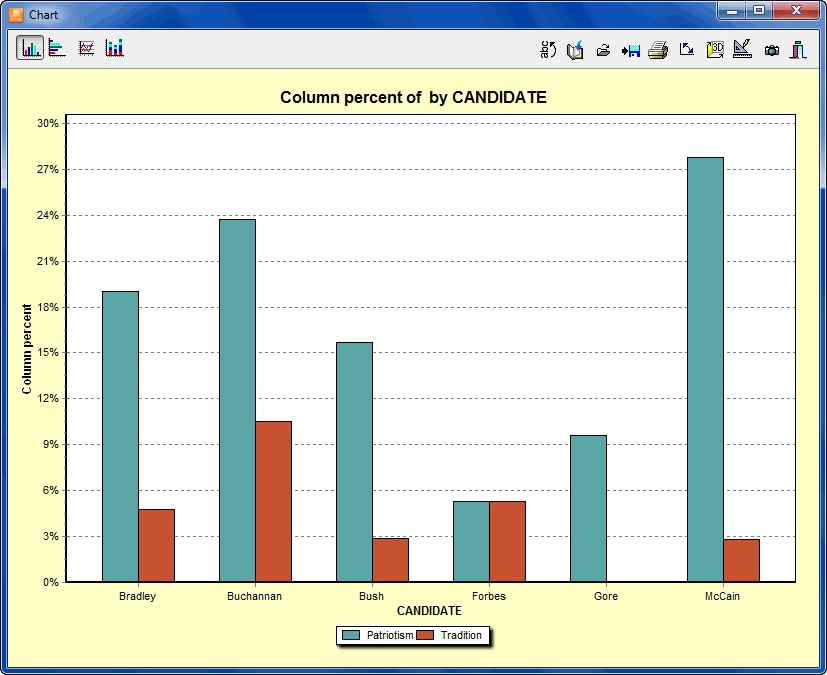
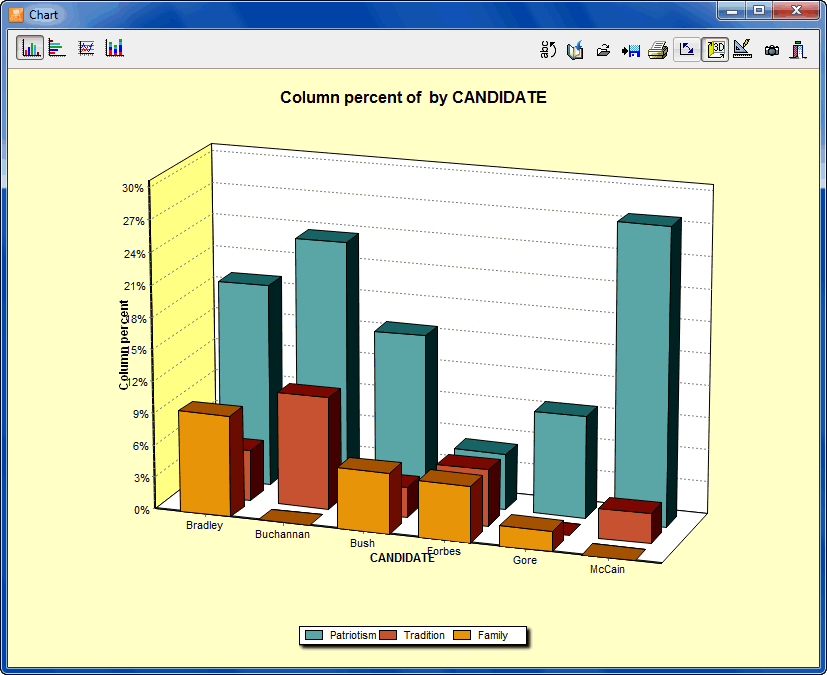
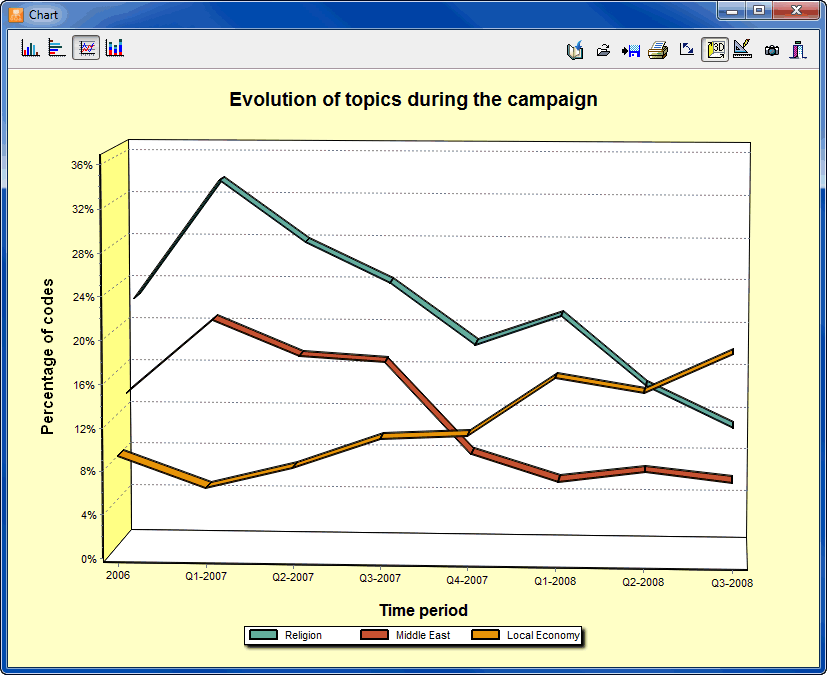
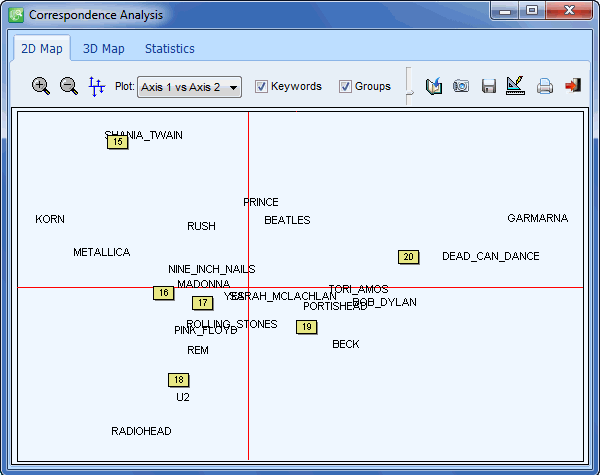
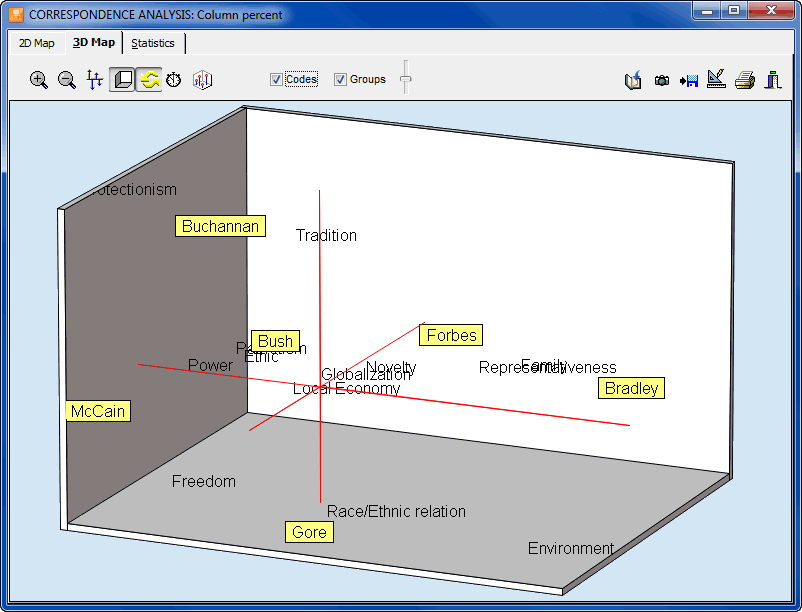
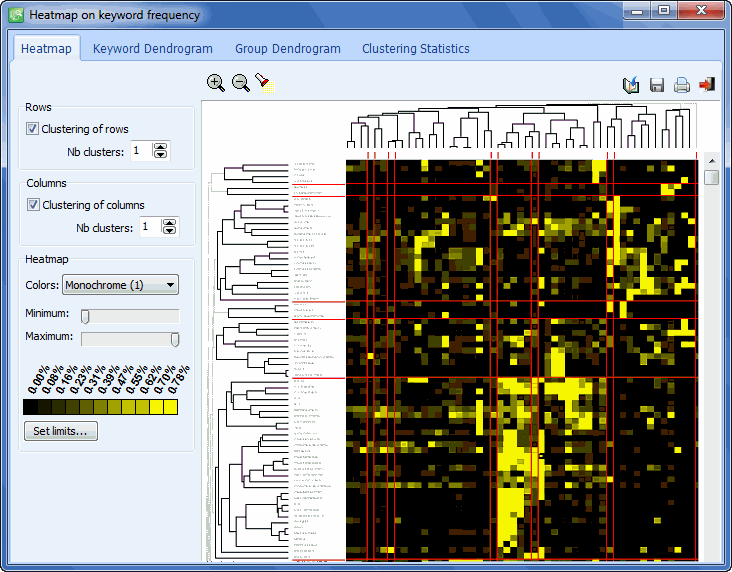
- The Coding by Variable tool is useful for identifying or testing potential code similarities or differences between subgroup of cases (categorical variable) or to assess the relationship between these codes and other numerical variables. Various statistical and graphical tools are used for this purpose such as contingency tables, association statistics, bar charts and line charts, heatmaps, correspondence plot, etc.
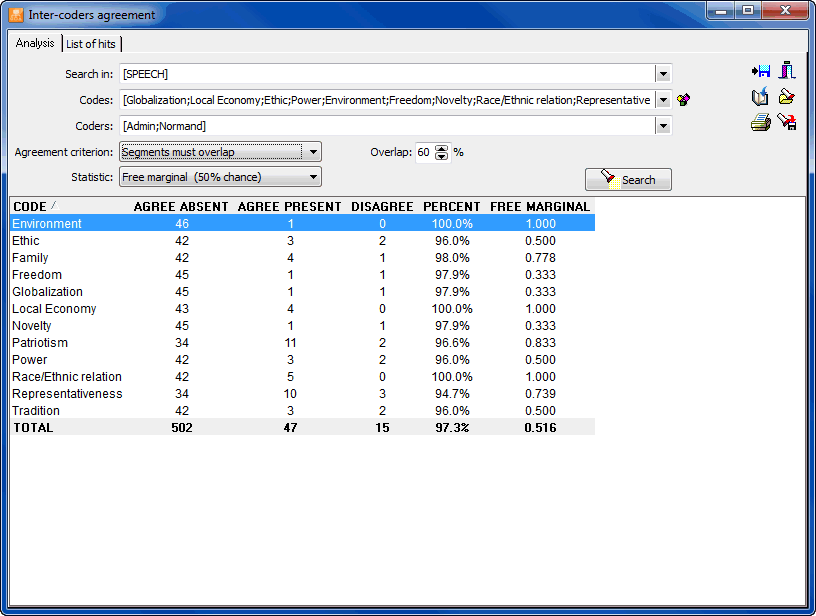
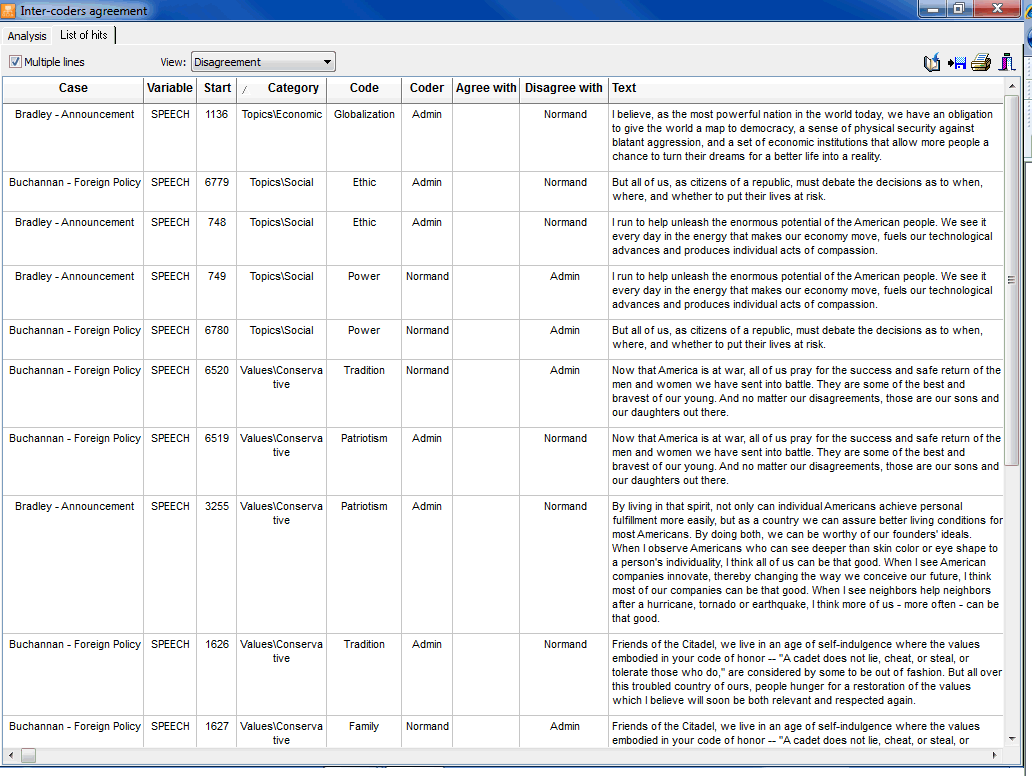
- The Coding Agreement tool is used to compare the consistency of coding between several coders. Such a tool can be useful to uncover differences in interpretation, clarify equivocal rules, identify ambiguity in the text, and ultimately quantify the final level of agreement obtained by those raters. Computes of percentage of agreement, correction for chances (Free Marginal, Scott's Pi, and Krippendorff's alpha), list of disagreements, etc.
- Optional Quantitative Content Analysis and Text Mining module. WordStat is a powerful quantitative content analysis and text mining software. When used as an add-on to QDA Miner, it analyzes words and phrases found in specific documents or in selected coded segments. WordStat can perform simple descriptive analysis or explore in greater details the relationships between words or categories of words and other numeric or categorical variables.
- Optional Statistical Analysis module. Simstat is a comprehensive statistical analysis application. Since it uses the same file format as QDA Miner, Simstat can be used to perform statistical analysis on any numerical data stored in a QDA Miner project file. It can also perform numeric and alphanumeric computation, transformation and recoding of variables, as well as advanced file management procedures such as data file merging, file aggregation, etc.
Miscellaneous features
Multilingual interface
- The program interface is currently available in English and in French. A Spanish version should be available soon. Contact us for information on the availability of other languages.
Output features
- Saving of tabular outputs to disk in HTML, XML, plain text, comma or tab separated value, MS Word or Excel format.
- Saving of graphics to disk and to clipboard as bitmaps, metafiles, JPG or PNG files.
- Documents may be exported to disk in plain text, RTF or HTML.
- Whole projects, including tagged documents, may be exported to disk in XML format.
Multi-users features
- The Security/Multi-Users feature allows to control users privileges and restrict access of selected features (prevent modification to documents, variables, or cases, prevent viewing codes assigned by other users, etc.).

- The Merge Projects feature allows one to combine two or more project files into a single one, allowing one to synchronize one's own work performed on different computers. As well, both an individual or various team members may work on the same set or different sets of documents and then merge them along with their associated codings into a single master project.
