 |
|
WordStat Features
TEXT PROCESSING CAPABILITIES
- Content analysis on short alphanumeric variable (up to 255 characters) and longer ANSI or RTF document (several mb).
- Dictionary moderated lemmatization and stemming (English, French, Italian and Spanish; contact us for other languages).
- Ability to call external text pre-processing EXE or DLL (sample English porter stemmer and n-grams transformation are include)
- Optional exclusion of pronouns, conjunctions, etc, by the use of user-defined exclusion lists (or stop list).
- Categorization of words or phrases using existing or user-defined dictionaries.
- Word categorization based on Boolean (AND, OR, NOT) and proximity rules (NEAR, AFTER, BEFORE)
- Word and phrase substitution and scoring using wildcards and weighting.
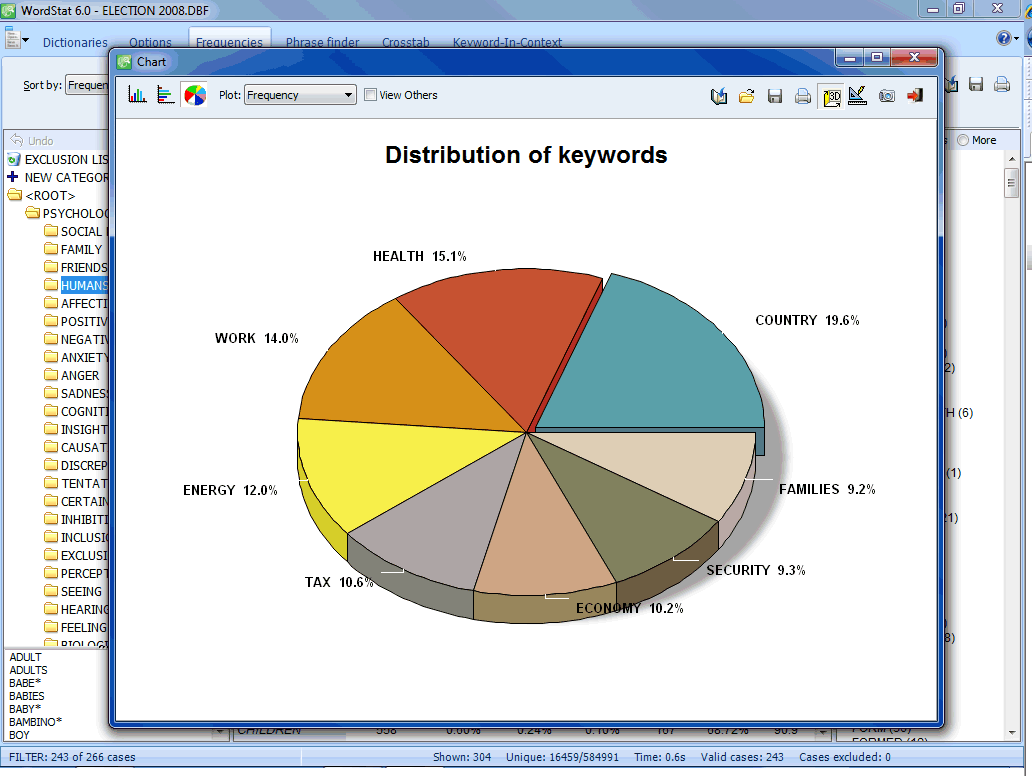
- Frequency analysis on keywords, phrases, derived categories or concepts, or user-defined codes entered manually within a text.
- Interactive development and easy maintenance of hierarchical dictionaries, taxonomies, or categorization schema.
- Drag and drop editor for easy assignments of words, phrases into categories!
- Ability to restrict the analysis to specific portions of a text or to exclude comments and annotations.
- Ability to perform an analysis on a random sample of cases.
- Integrated spell-checking with support for different languages such as English, French, Spanish, etc.
- Integrated thesaurus (English only) to assist the creation of taxonomies and comprehensive categorization schemas.
- Powerful case filtering on any numeric or alphanumeric field and on code occurrence (with AND, OR, and NOT boolean operators)
- Prints presentation quality tables
- Imports MS Word, WordPerfect, RTF and HTML.
- Exports any table to Excel, ASCII, Tab separated or comma separated value files, or HTML files.
- Flexible keyword highlighting (the text editor can display all categories using different colors).
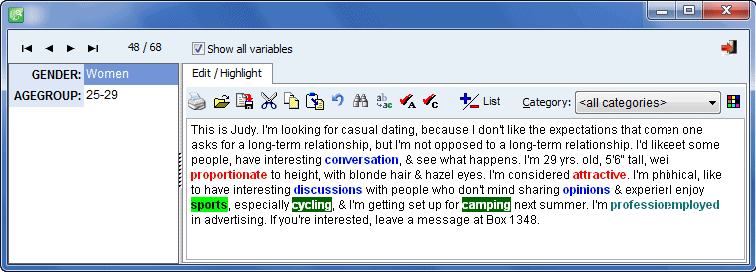
UNIVARIATE KEYWORD FREQUENCY ANALYSIS
- Univariate word frequency analysis (word or category count and record occurrence).
- Word x word co-occurrence matrix.
- Word x case data matrix.
- Integrated multidimensional scaling with 2D and 3D maps.
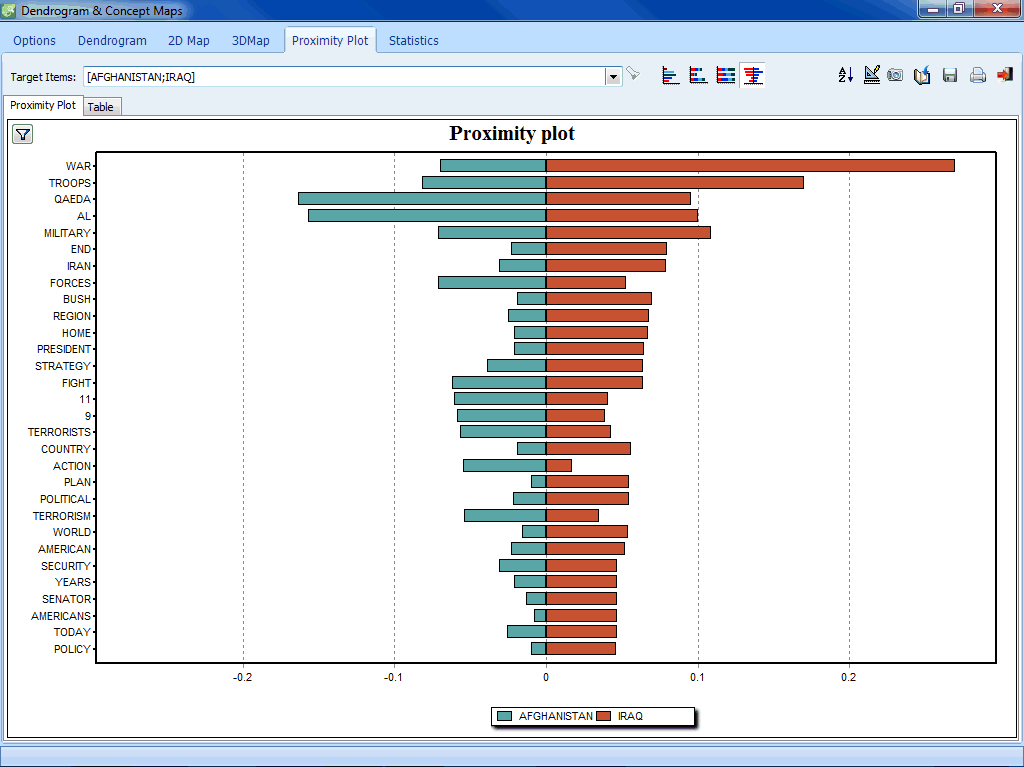
- Proximity plot.

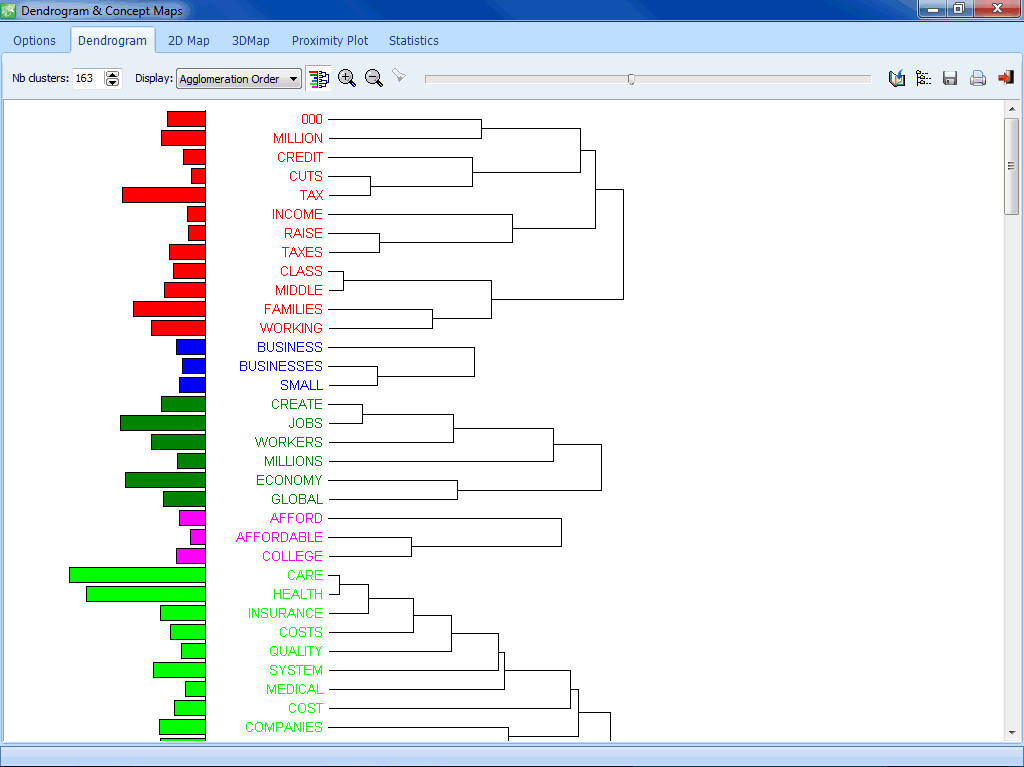
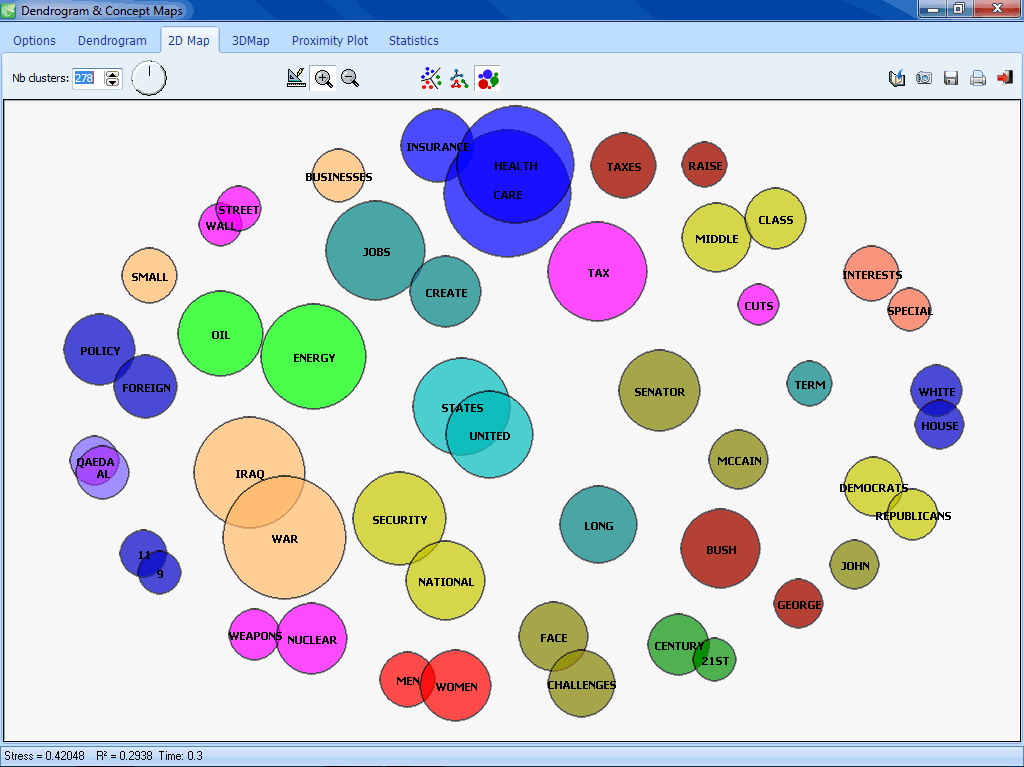
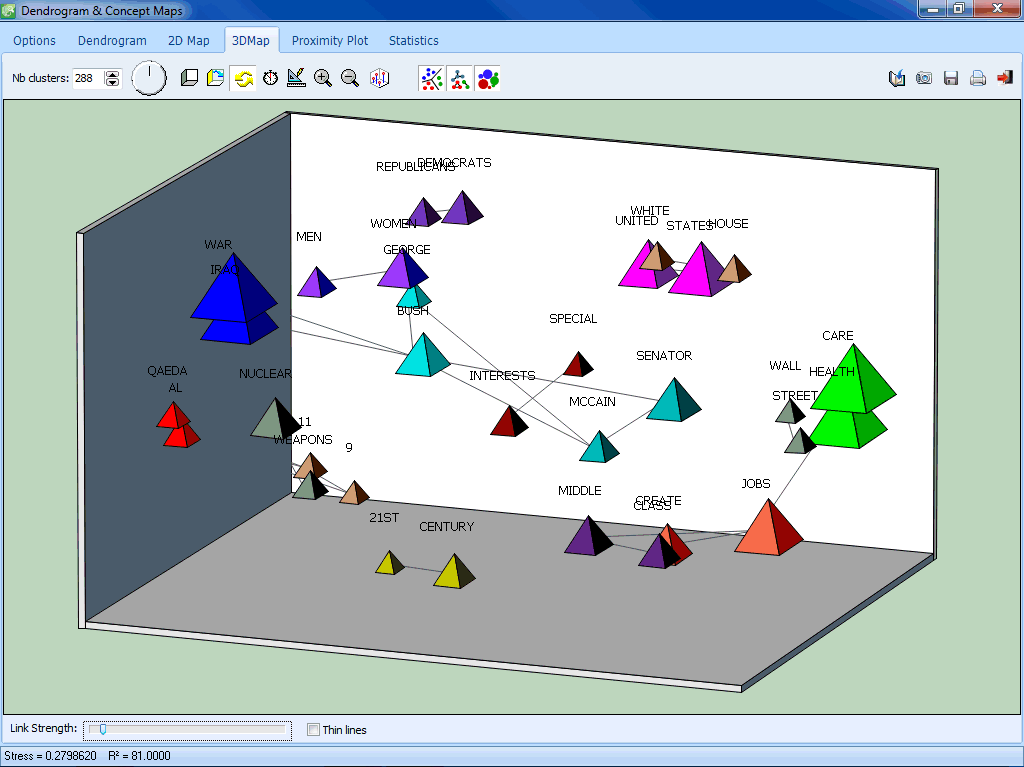
FEATURE EXTRACTION
- Topic modeling tool automatically extract topics by applying factor analysis on word x segment matrices.
- Vocabulary finder extracts technical terms, product and company names as well as common misspellings.
- Pattern based named-entity extraction.
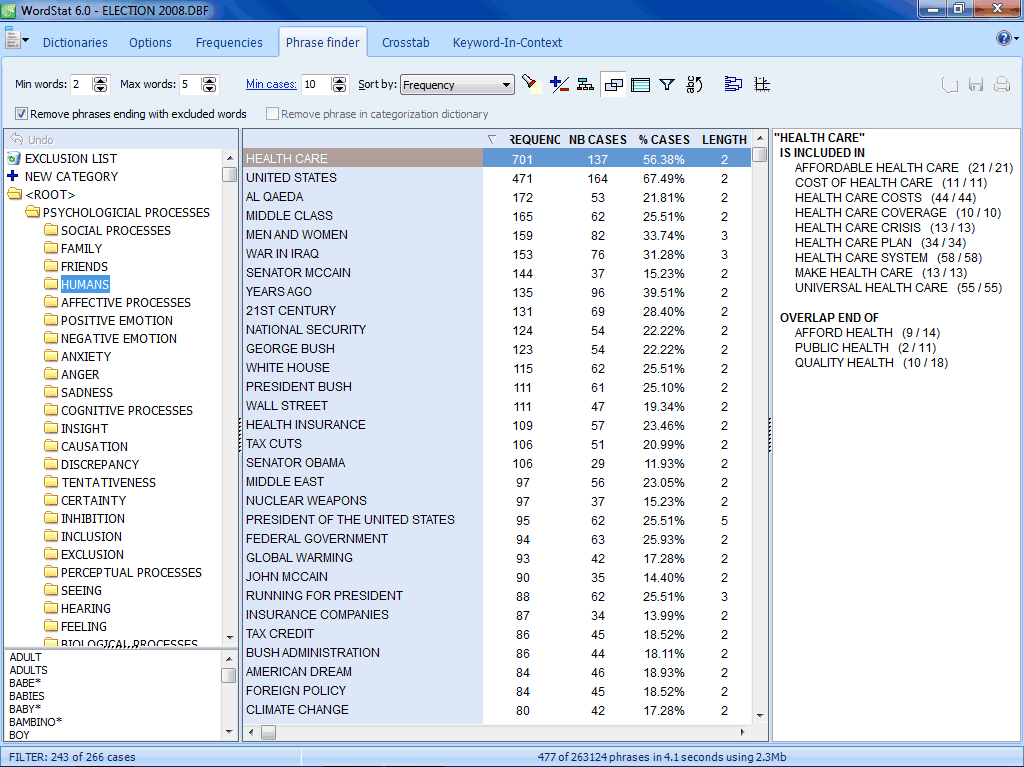
- Phrase finder allows one to easily identify recurring phrases and expressions
NORM CREATION AND COMPARISON
- Ability to create norm files based on frequency analysis of words or content categories.
- Comparison of obtained frequencies to previously saved norm files.
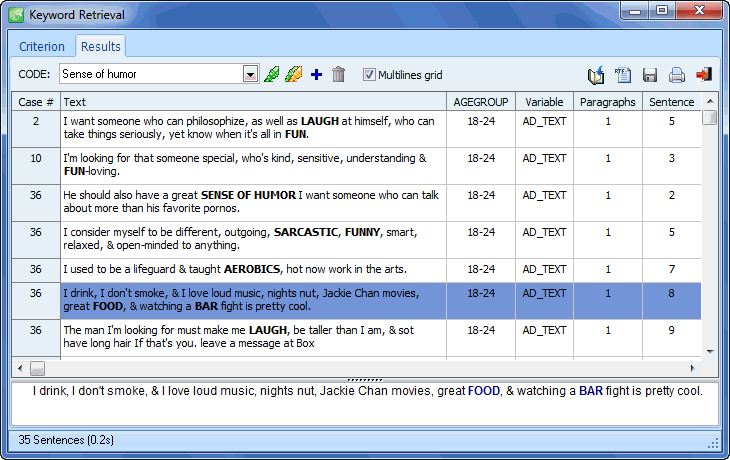
KEYWORD RETRIEVAL FUNCTION
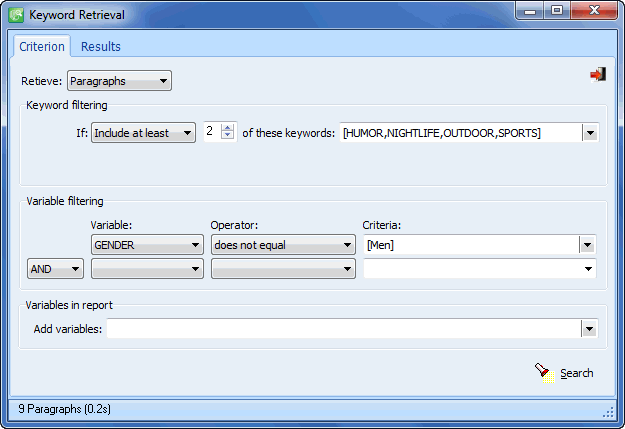
- A powerful keyword retrieval function allows identification of text units (documents, paragraph or sentences) containing one keyword or a combination of keywords with optional filtering of cases.
- Ability to attach QDA Miner codes to retrieved segments.
- Retrieved segments may be exported to disk in tabular format (Excel or delimited text files) or as text reports (Rich Text Format).
KEYWORD CO-OCCURRENCE ANALYSIS
- Integrated clustering and dendrogram display of keyword co-occurrence.
- First- and second-order proximity analysis.
- Proximity plot to easily identify all keywords that co-occurs with a target keyword.
- 2D and 3D multidimensional scaling on either joint frequency or co-occurrence of words or categories.
- Flexible keyword co-occurrence criteria (within a case, a sentence, a paragraph, a window of n words, a user-defined segment) as well as clustering methods (first- and second-order proximity, choice of similarity measures).
- Easy text retrieval from dendrogram or proximity plots.
ANALYSIS OF CASE OR DOCUMENT SIMILARITY
- Hierarchical clustering, multidimensional scaling and proximity plot may be used to explore the similarity between documents or cases.
MULTIPLE RESPONSES AND COMPARISONS
- Can perform univariate frequency analysis and crosstabulation on information stored in several alphanumeric fields (memo or string variables).
- Comparison of keyword occurrence between different fields.
- Computes inter-raters agreement measures (pct. of agreement, Cohen's Kappa, Scott's Pi, Krippendorff's R and r-bar, free marginal) based on codes manually entered in different variables.
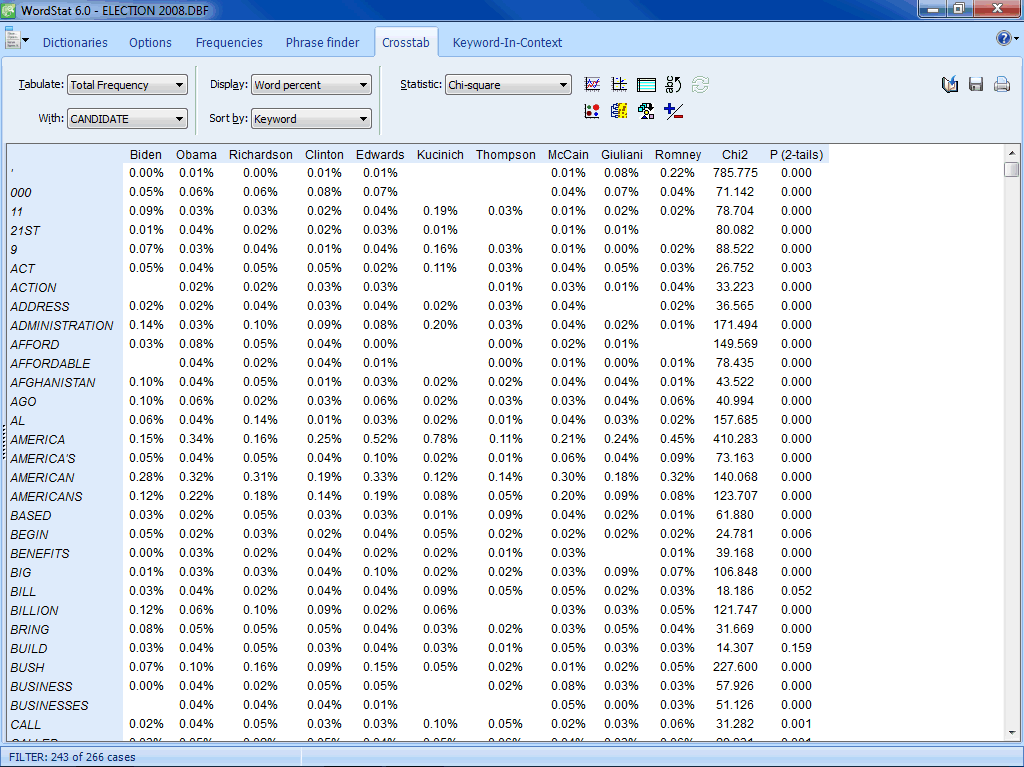
BIVARIATE COMPARISONS BETWEEN SUBGROUPS
- Bivariate comparison between any textual field and any nominal or ordinal variable (such as the sex of the respondent, specific subgroups, years of publication, etc.).
- Choice between 11 different association measures to assess the relationship between word occurrence and nominal or ordinal variables (Chi-square, Likelihood ratio, Tau-a, Tau-b, Tau-c, symmetric Somers' D, asymmetric Somers' Dxy and Dyx, Gamma, Person's R, Spearman's Rho)
- Computation statistics on either absolute or relative frequency
- Ability to sort matrix in alphabetic order of words, by word frequency or word occurrence, on the obtained statistics or on its probability.
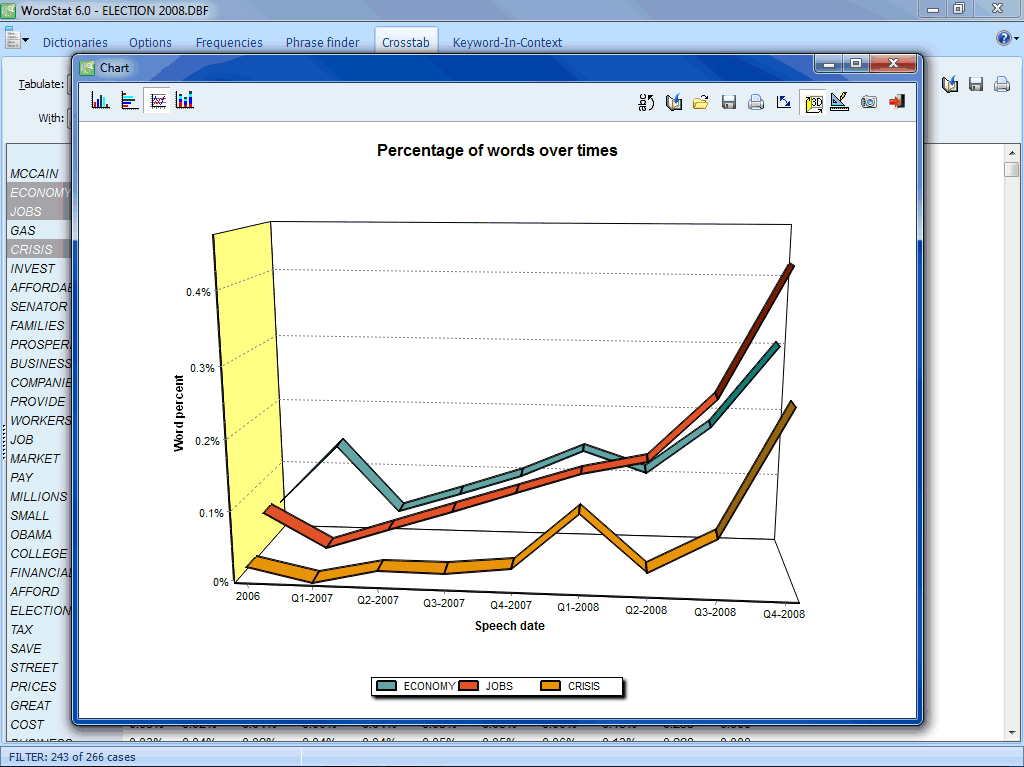
- Visually compare items between subgroups using bar charts and line charts.

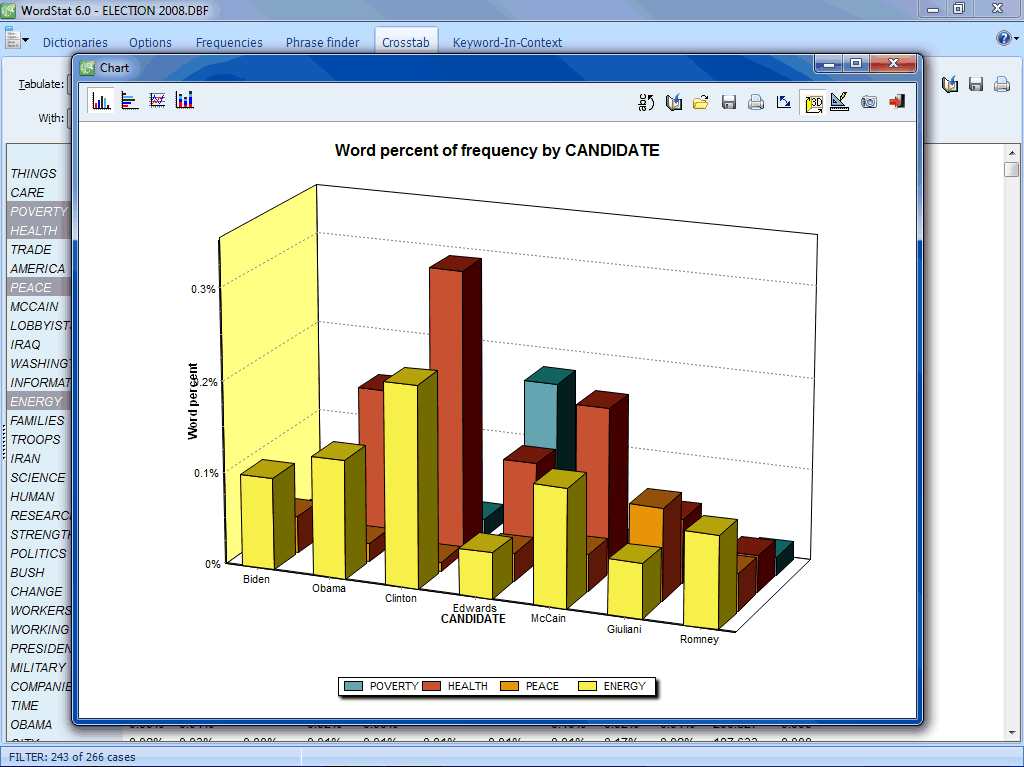
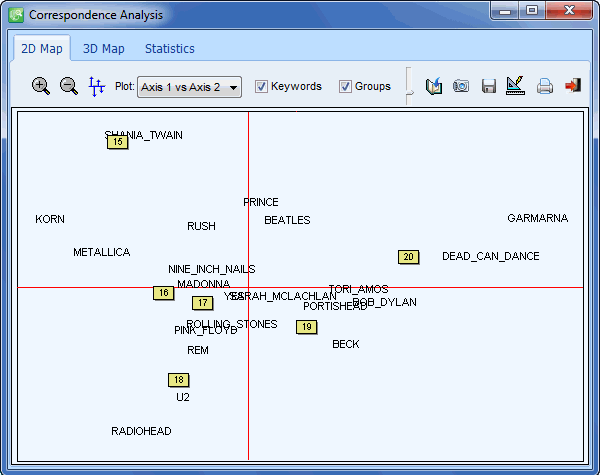
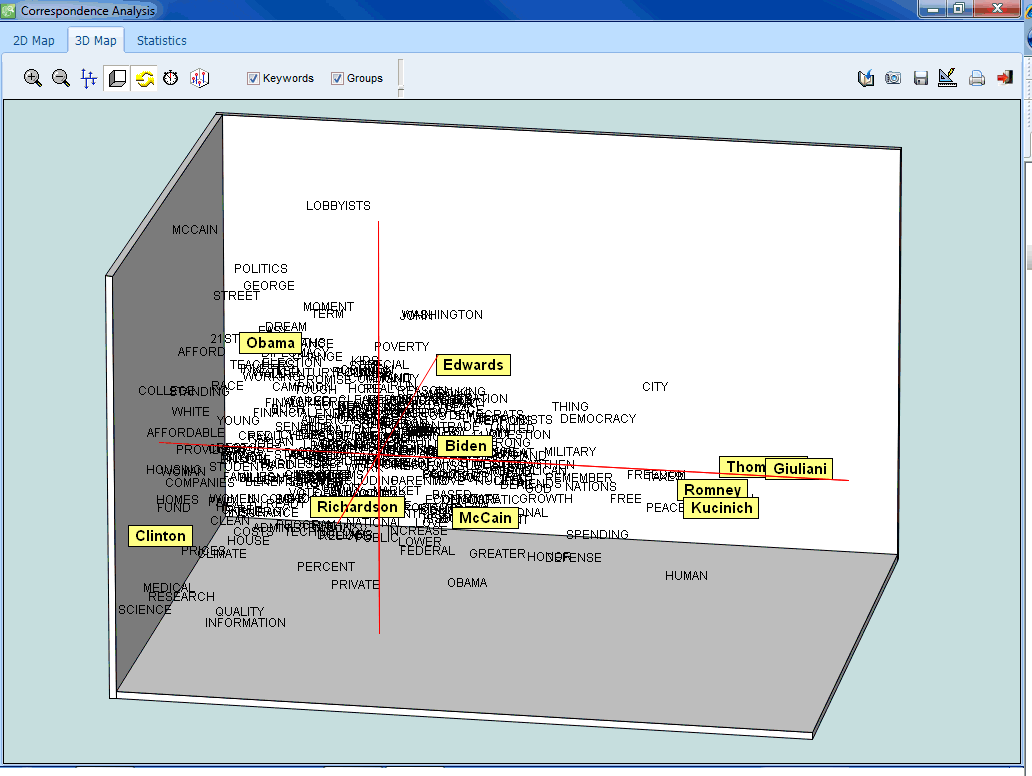
- Correspondence analysis (statistics, 2D & 3D joint plots). This feature is accessible from the crosstab page and allows one to see graphically the relationship between nominal variables and codes resulting from a content analysis.
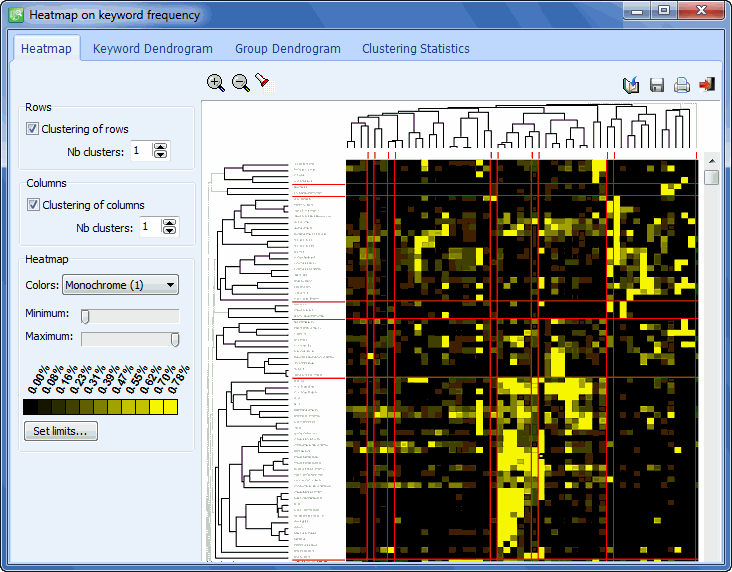
- Heatmap plot (with dual-clustering of keywords and variables)
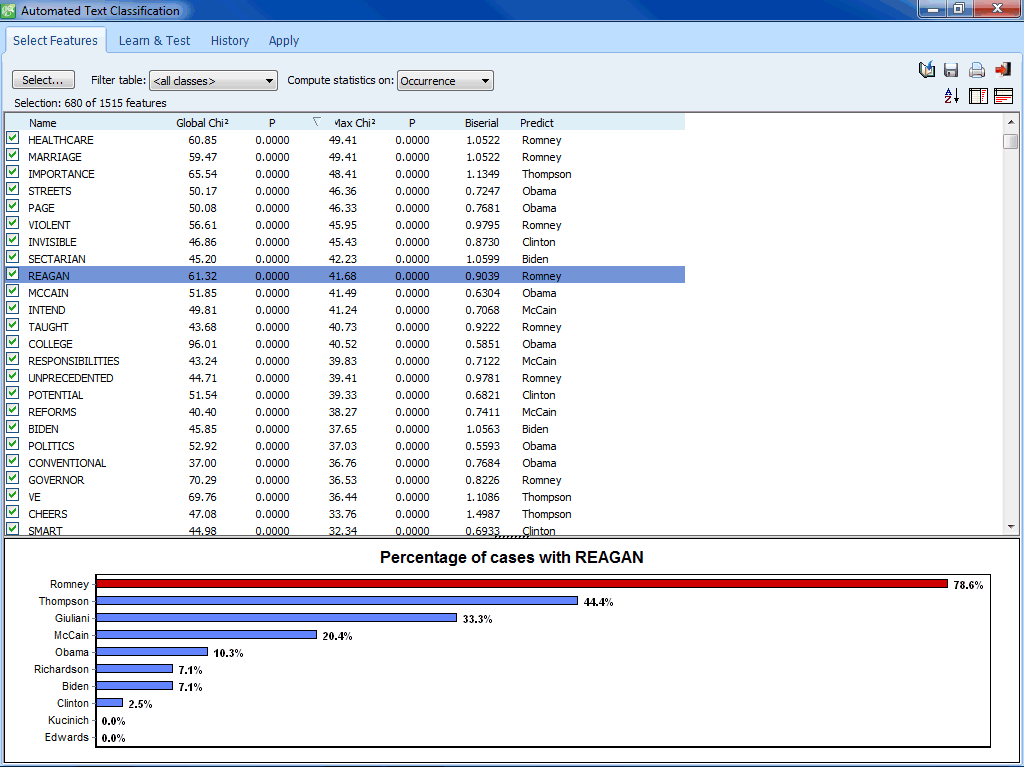
AUTOMATED TEXT CLASSIFICATION
- Machine learning algorithms (Naive Bayes and K-Nearest Neighbors) for document classification.
- Flexible feature selection for automatic selection of best subsets of attributes.
- Numerous validation methods (leave-but-one, n-fold crossvalidation, split sample).
- Experimentation module allows easy comparison of predictive models and fine-tuning of classification models.
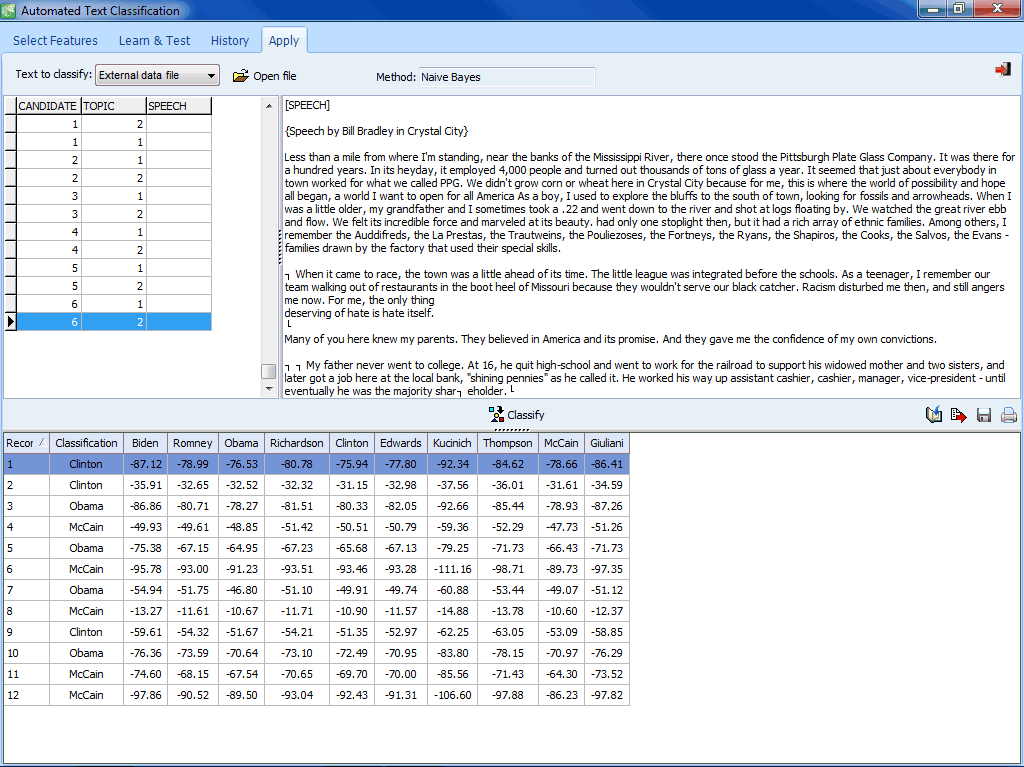
- Classification models may be saved to disk and applied later using either a standalone document classification utility program, a command line program or a programming library . Note: The command line and the programming library are part of WordStat Software Developer's kit (SDK) which is sold separately.


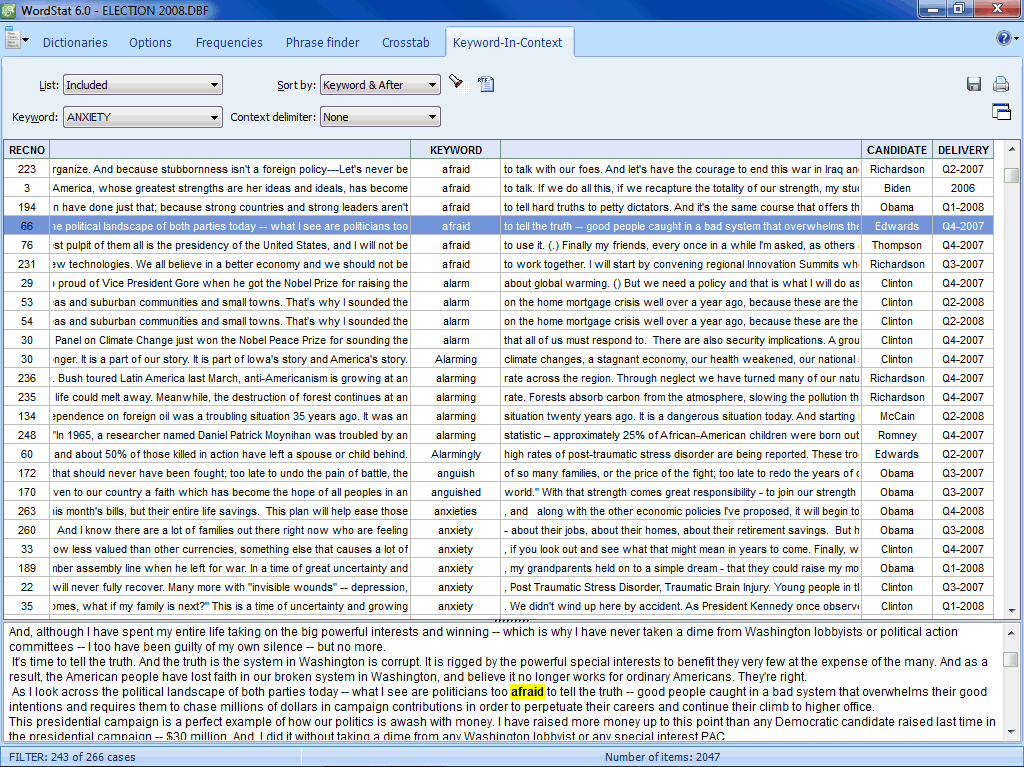
KEYWORD-IN-CONTEXT (KWIC)
- Ability to display a KWIC table to examine the textual context of a word, word pattern, or category.
- Ability to sort the table on any independent (numeric) variables.
- Ability to jump from a KWIC keyword to the textual variable in order to view or edit the original text.
- KWIC list can be saved in data files for further processing.
- Customizable KWIC display (paragraph, sentence or user defined segment).
- Concordance report (displays all hits as a list of paragraphs, sentences or user defined segments)
FULL INTEGRATION WITH A STATISTICAL SOFTWARE
- Alphanumeric variables can be stored in the same file as all other numeric variables.
- Variable selection, statistical analysis and content analysis are performed within the same application program.
- Matrix outputs are automatically added to existing statistical outputs.
- New variables representing occurrence of words, keywords or concepts can be added to the existing data file or exported to a new data file in order to be submitted to further statistical analysis (such as cluster analysis on words or cases, principal coordinate analysis, correspondence analysis, multiple regression, etc.).
- Data can be imported from and exported to different file format including dBase, Paradox, Excel, Quattro Pro, Lotus 1-2-3, SPSS for DOS, SPSS for Windows, comma or tab separated text files, etc.
- Ability to perform numeric and alphanumeric transformation or to apply filters on records of the data file to restrict the analysis to specific subgroups. .
UTILITY PROGRAMS
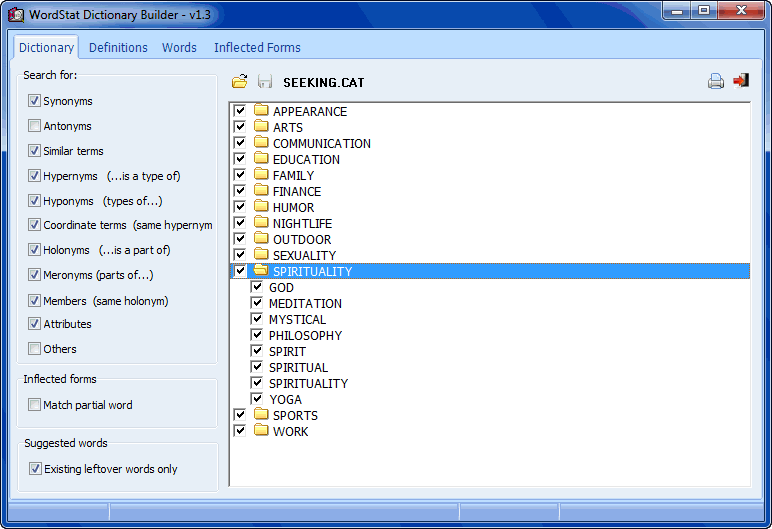
- Dictionary building assistant to find related words (synonyms, antonyms, holonyms, meronyms, hypernyms, hyponyms) in aWordNet based thesaurus (English only). (100,000 synonyms, 120,000 root words)


- WS Document Classifier, a small standalone application to apply previously saved categorization and classification models to external documents.
- WSTOOLS - Utility program to easily import documents of any
size into Simstat database files.
- Various file formats may be
directly imported such as:
- Plain text (with optional DOS ASCII to Windows ANSI conversion)
- HTML (with or without removal of HTML tags)
- RTF
- MS Word
- WordPerfect
- Adobe PDF
- Optional removal of leading and trailing spaced and hard returns.
- Extraction of numeric and alphanumeric variables from documents.
- Extraction options may be saved on disk and later retrieved.
- Documents may be stored as plain ANSI text or as RTF documents.
- Various file formats may be
directly imported such as:
