WordStat 9 New Features
1. Full Unicode Support
We always try to select language-independent text analytics techniques. This has allowed users to analyze text data in more than 50 languages. However, to analyze languages not supported by their default Windows installation, the user needed to change some Windows settings. And while it was possible to analyze datasets in multiple languages, some combinations of languages were simply not possible. The new Unicode version of WordStat allows one to analyze any of these without any setting changes as well as new languages previously not supported such as Chinese, Japanese, or Thai. Word segmentation routines for the previous three Asian languages have also been added.

2. Integration of R and Python Pre- and Post-Processing Scripts
In 2018, we introduced the possibility to create Python preprocessing scripts to WordStat 8. Version 9.0 extends this capability by offering the possibility to create preprocessing scripts in R as well. More importantly, it is now possible to create post-processing scripts in those two programming languages allowing one to perform custom analysis on the original or transformed text data or on quantified results obtained through content analysis on those documents. Such a feature offers endless possibilities to extend the features of WordStat such as implementing new machine learning algorithms, advanced statistical modeling techniques, or custom data transformation. Sample scripts have been included to compute text readability metrics, detect languages, apply other topic modeling techniques (LDA or STM) or create predictive models using machine learning (SVM, kNN, etc.).
![]()

3. Automatic Spelling Correction
A new spell-checking engine has been written from scratch to achieve much faster and more accurate spelling corrections, allowing the implementation of an automatic spelling correction feature with minimal impact on the existing text processing speed of WordStat. The intelligent spelling correction can even correct the spelling of unknown terms such as technical vocabularies, proper nouns, etc. Results can be automatically saved to the substitution list for revision and corrections.
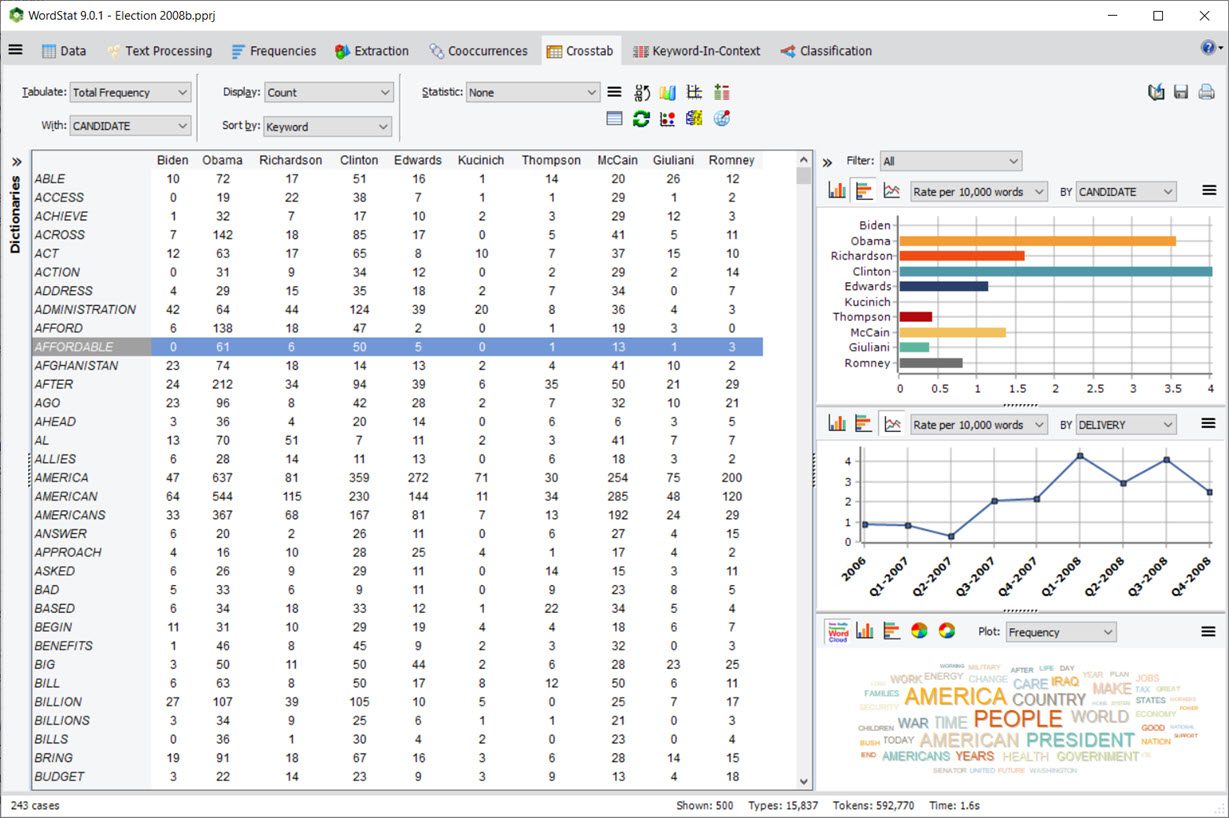
4. Crosstabulation with Charting Panels and Filtering
The crosstab page now includes a chart panel allowing one to quickly plot the distribution of selected rows of the crosstabulation table for the values of the currently selected variable or any other variable. A filtering list box also allows one to analyze such distributions for a single value or a set of values of the selected variable.
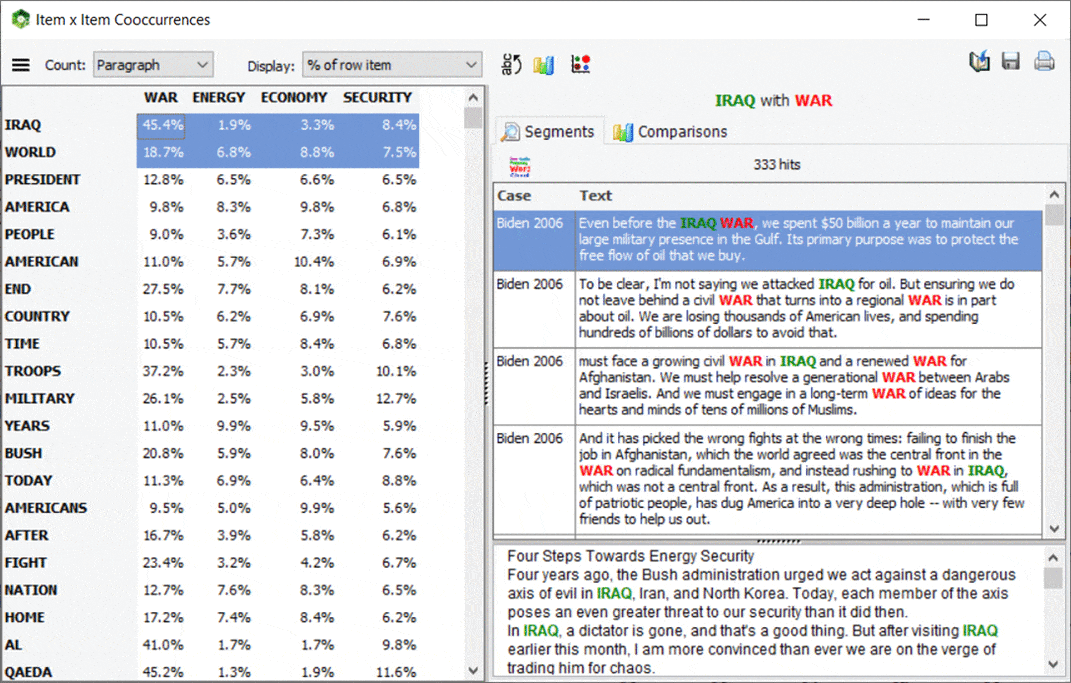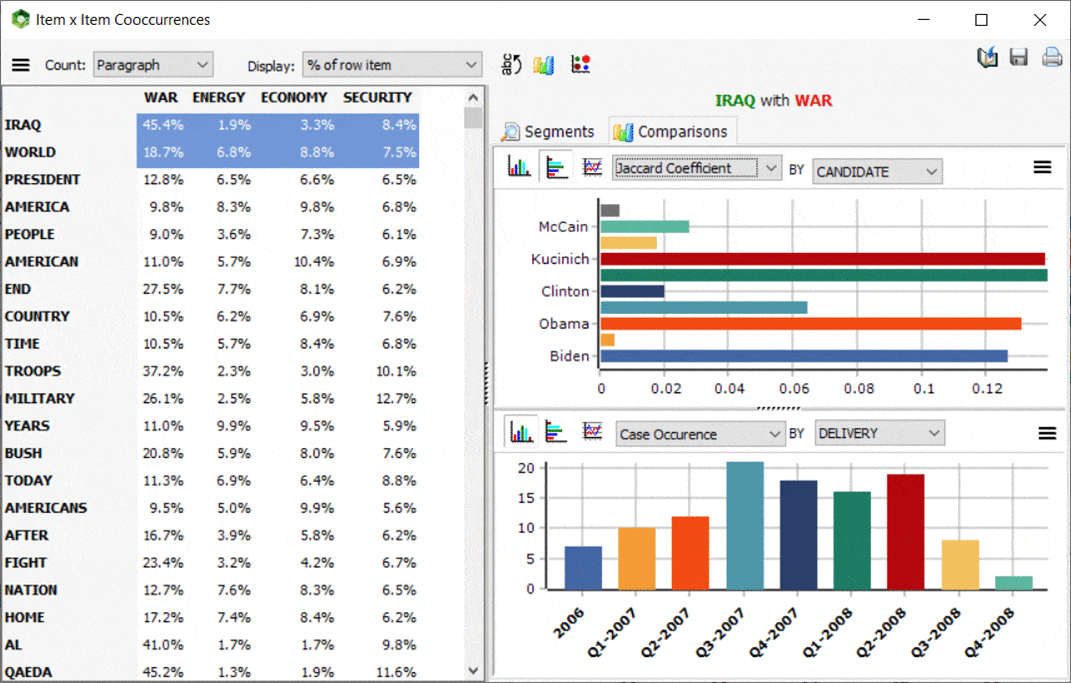
5. Interactive Co-occurrence Matrix
A new interactive matrix feature has been added to the co-occurrences page allowing one to focus on specific co-occurrences. The main results consist of a table displaying a choice from various co-occurrence statistics. Such matrix is also highly interactive allowing one to transform specific rows into new columns or vice versa using simple drag-and-drop operations. A charting panel on the left also allows one to assess the distribution of a specific co-occurrence across other variables. One may also obtain a quick view of all text segments associated with a specific co-occurrence. This new feature of WordStat may also be called from the frequency list by selecting target items (words or content categories) that should be displayed as columns, right-clicking, and selecting Co-Occurrence Matrix.
6. Importation of Nexis UNI and Factiva Files
Introduced in QDA Miner 6.0 in 2020, it is now also possible in WordStat to import news transcripts from the LexisNexis and Factiva output files. After selecting one or multiple .DOCX or RTF files obtained from those services, WordStat will extract and store in separate variables the title and body of the news transcript, its source, the publication date, and other relevant information. Such a feature should prove useful for reputation management, brand management, crisis communication, media framing analysis, comparative media studies, etc.

7. Batch Processing of Topic Models
Choosing the number of topics to extract using topic modeling techniques remains a question for which there is, to our knowledge, no definitive answer. We may even raise doubts as to whether such an optimal number exists. In fact, one may even suggest that information obtained using different settings may well serve different purposes or reveal different aspects of a reality. In such a context of uncertainty, researchers often want to compare various solutions. The new batch processing feature allows one to compute multiple topic models by systematically varying the number of topics to extract, and for the probabilistic method (e.g. NNMF), to perform several runs using the same settings in order to assess the stability of the results. All topic model solutions are temporarily aggregated in the report manager allowing one to compare solutions obtained in multiple runs using different settings.
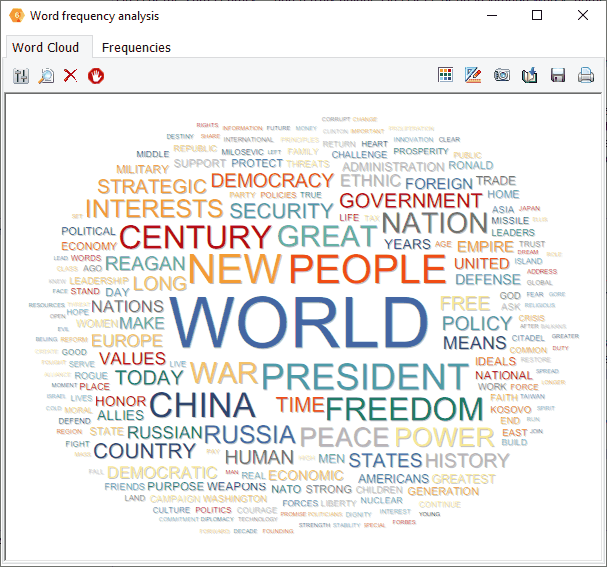
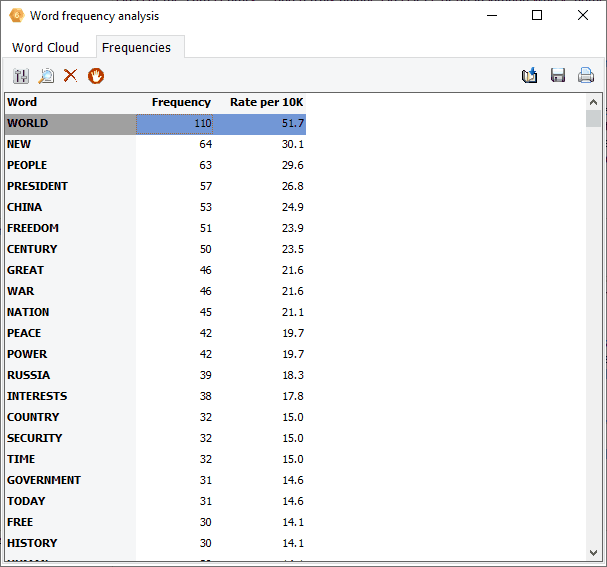
8. Create Word Clouds on Keyword Retrievals & KWIC Results
Interactive word clouds and word frequency tables can now be obtained directly on keyword retrieval and keyword-in-context (KWIC) results allowing one to quickly identify words associated with specific content categories, or those appearing, before, after a specific target item.
9. More Powerful Proximity Rules
The number of conditions in proximity rules has been increased from four to a maximum of twenty conditions. If you believe it is not enough, let us know.

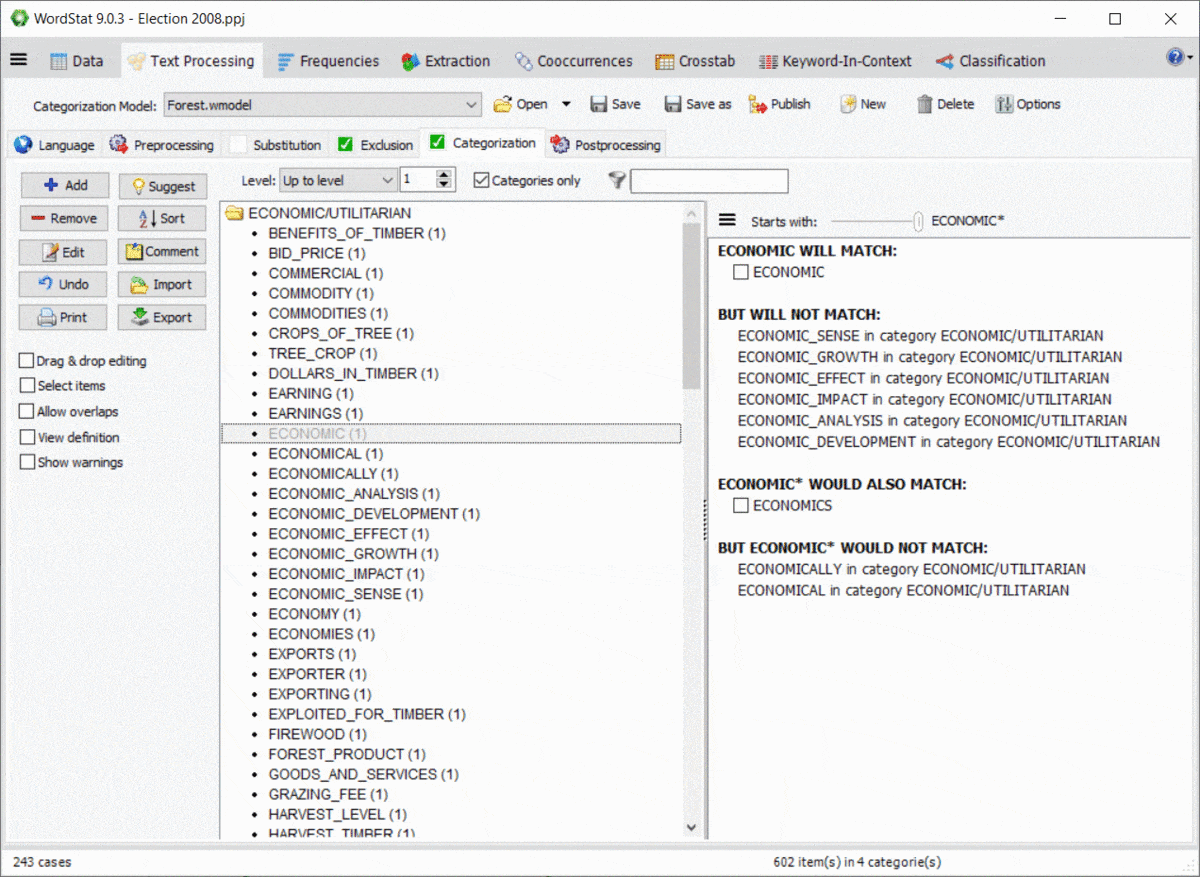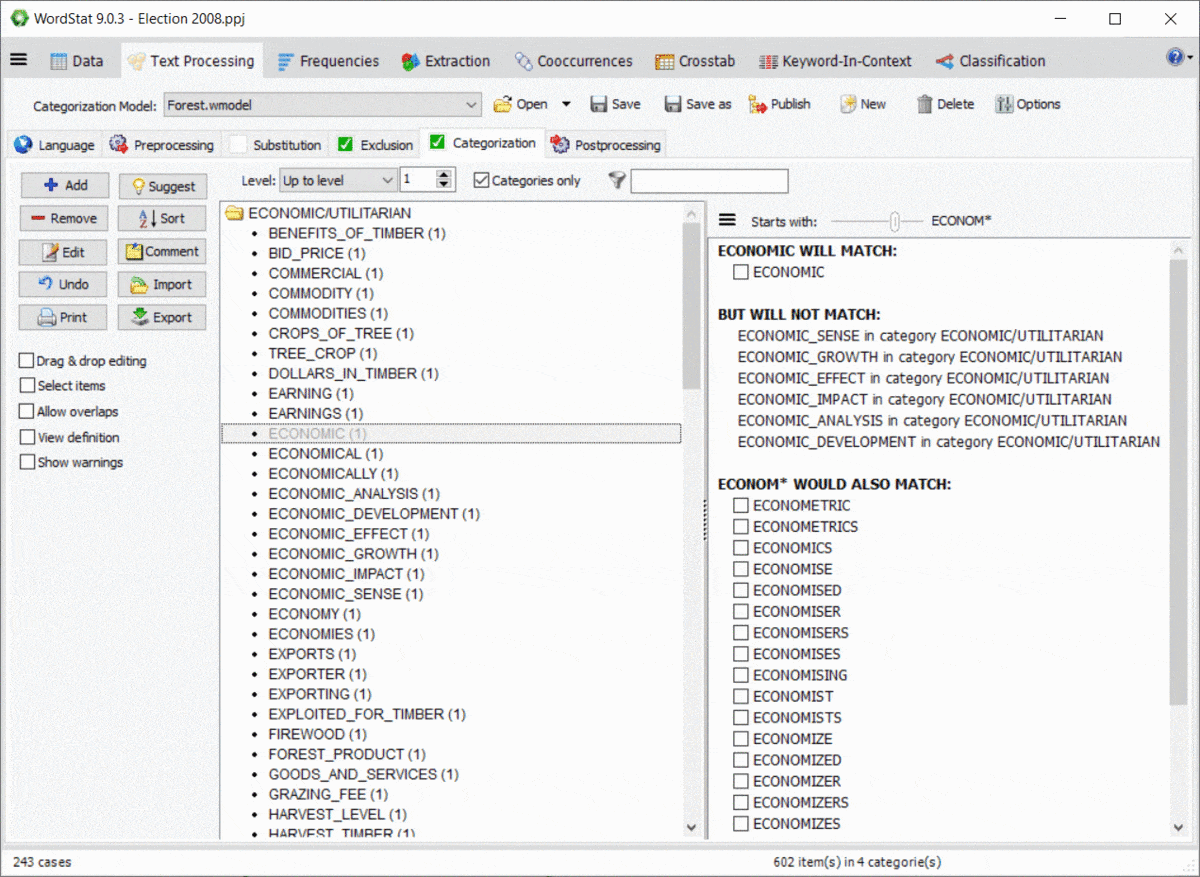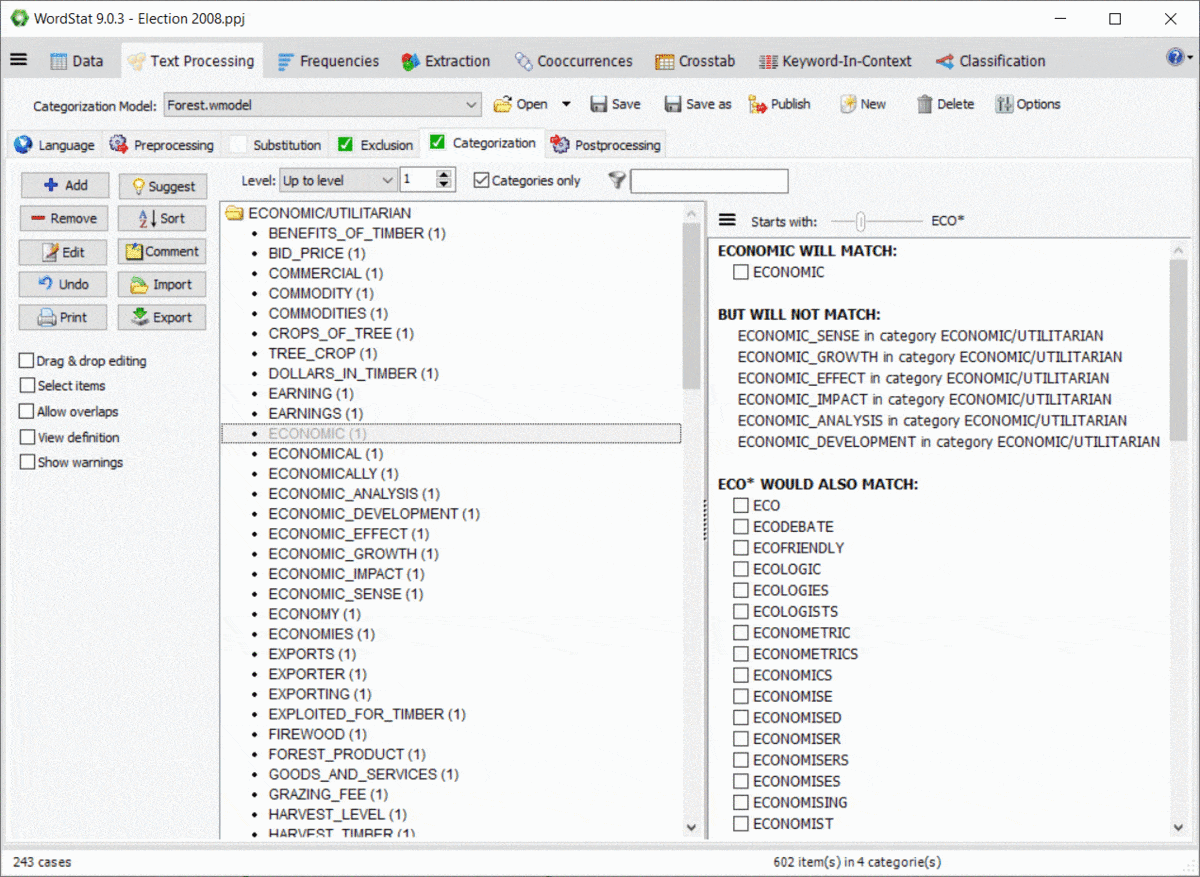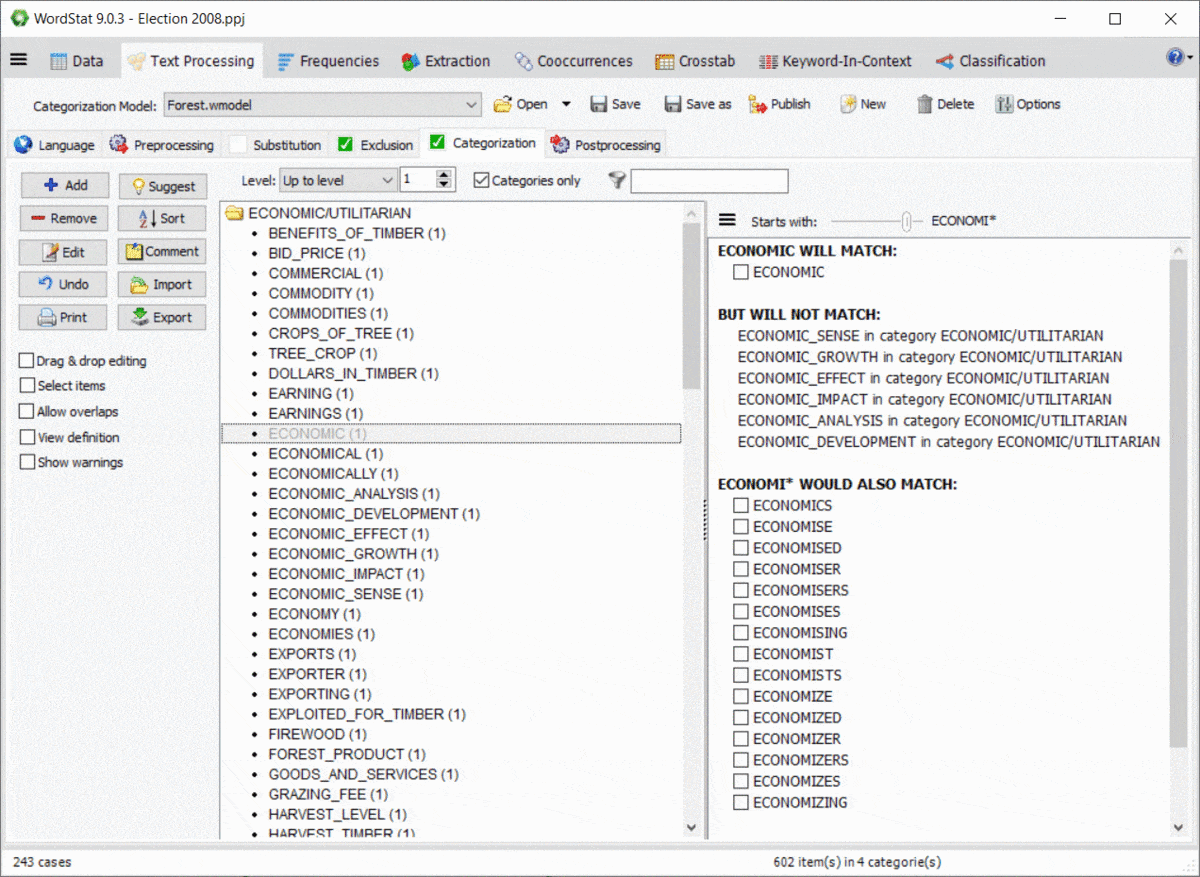
10. Preview Effect of Wildcards and Dictionary Interactions
Using wildcards in a dictionary is quite powerful yet potentially troublesome since it could match items that you may not have thought of. For example, an entry like TAX* may allow you to match TAX, TAXES, TAXATION, but will also match words such as TAXI, TAXONOMY, TAXIDERMY, etc. Also, WordStat rules for matching items and preventing double-counting may also produce unexpected results caused by other entries in your categorization model. A new panel on the right of the exclusion and categorization pages allows you to easily identify new entries that would be matched using a *wildcard at the end of a word but also of possible conflicts with other entries in your dictionary.
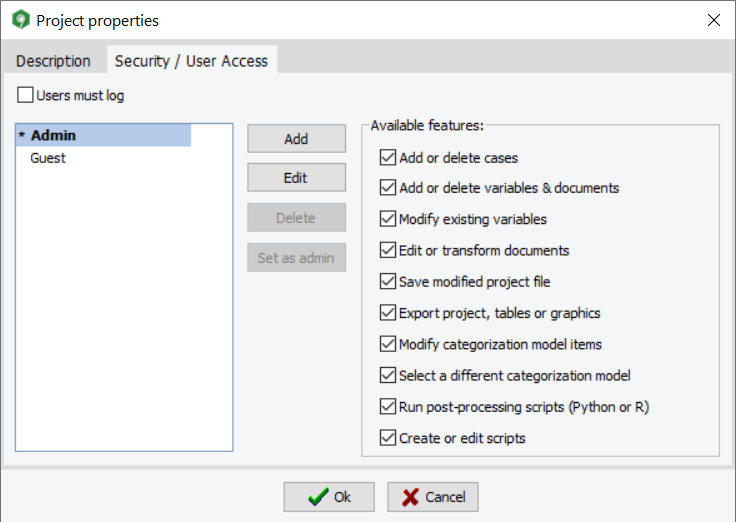
11. Password protection of project files
WordStat 9.0 now offers the possibility to password protect project files, restricting the access of specific projects to authorized users. A dialog box allows the project administrator to create new user accounts and specify which operation each user can perform. One may limit data editing, data importation, or transformation, as well as exportation of project data, tables, and graphics. Alternatively, you may choose to let the users perform any transformation they want but prevent them from saving the project file.
12. New Options for Cleaning Data
The preprocessing page now includes options to automatically remove URLs from text messages as well as speakers’ designations in news and interview transcripts.
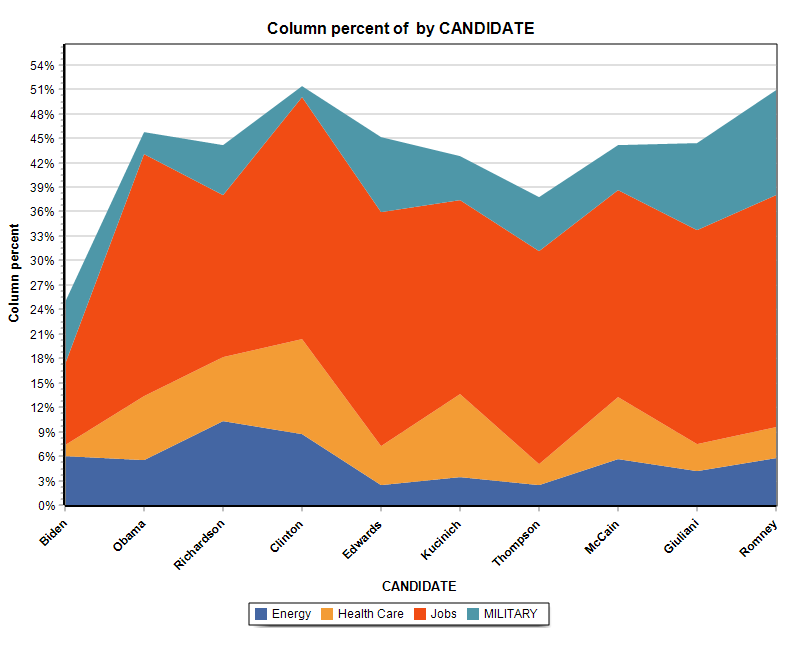
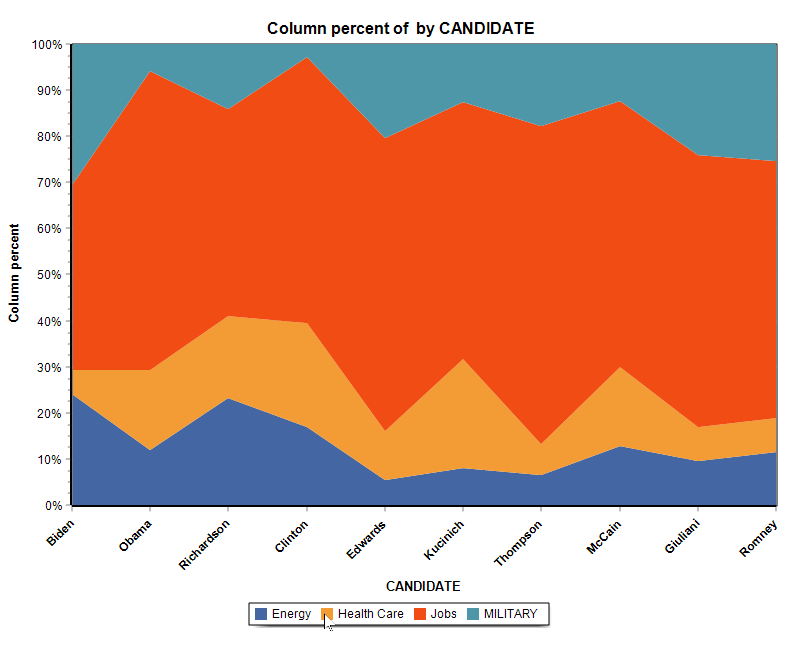
13. New Stacked Area Charts
The charting feature of the Crosstab page adds the possibility to create two types of stacked area charts.
14. Colored Items in Correspondence Plot
Color gradients may now be used to represent the position of specific items or variable classes on the third (depth) dimension or 2D and 3D correspondence plot. Up to four colors may be chosen to create those gradients.

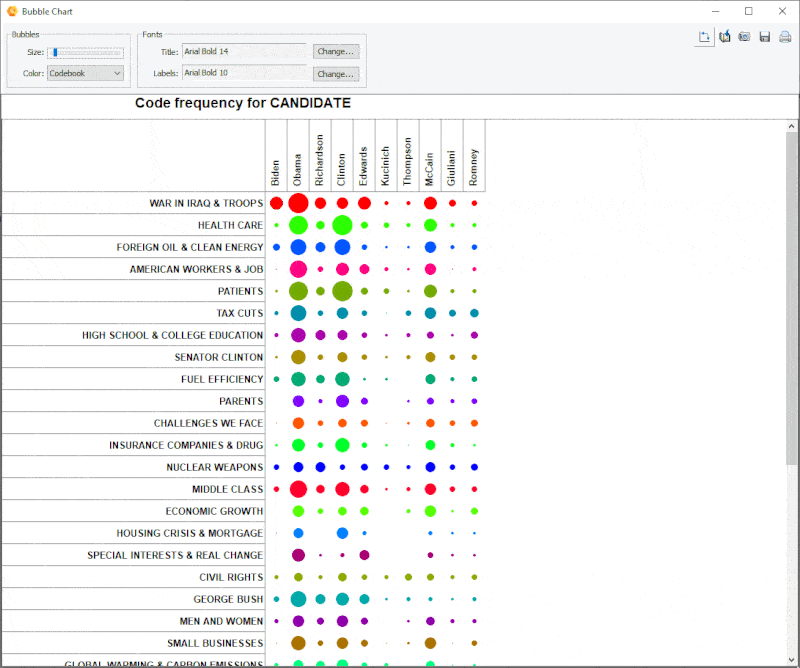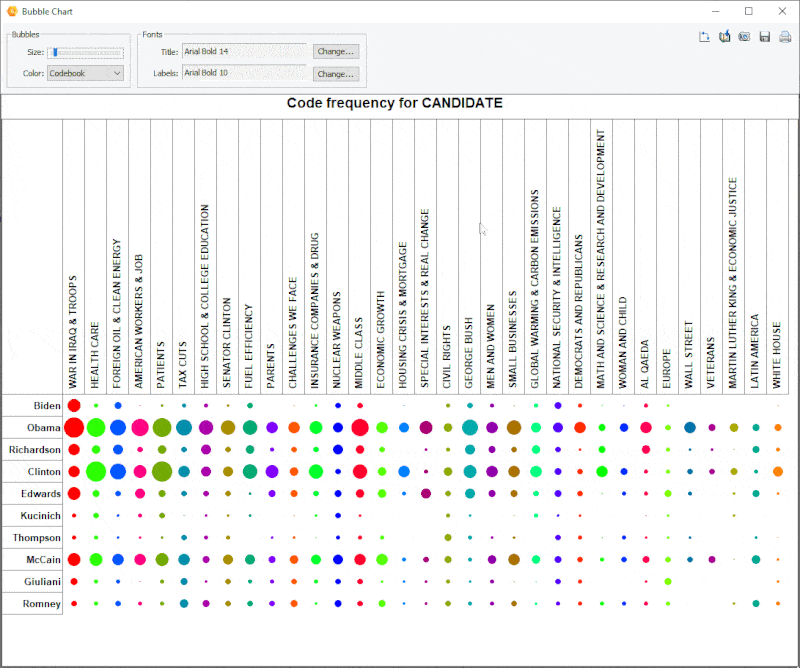
15. Improved Bubble Chart
It is now possible to transpose rows and columns of bubble charts.
16. Link Analysis Buffer
A link analysis buffer allows one to move back to previous link diagrams and then forward.
17. Faster and More Precise Topic Enrichment
WordStat goes beyond typical topic modeling, offering ‘a unique topic enrichment feature that identifies associated phrases, potential exceptions, and misspellings. It also generates relevant topic names automatically. With version 9, this topic enrichment feature is now twice as fast as before and performs better word-sense disambiguation for a more accurate list of exceptions. It also provides better suggestions for spelling corrections.
18.Improved Speed and Accuracy of Existing Spelling Corrections
The existing spelling correction feature is now up to 30x faster, requiring only a second or two to suggest spell corrections for tens of thousands of unknown words.
19. New .PPRJ File Format
A new file format with a new file extension (.pprj) was created, providing improved support for Unicode data. However, WordStat 9 retains backward compatibility with the prior versions of all our software and can open and analyze current project files (.ppj) created by QDA Miner, SimStat, or older versions of WordStat.
20. Numerous Additional Improvements
Several additional options and interface improvements have been made to existing dialog boxes, graphics, data management, and data analysis features.
New features in version 8 can be viewed here.
